What is Data Fabric?
Here’s a look at how data fabrics work, why they matter, the difference between data fabric, data mesh, and data lakes, plus real-world examples and business benefits.
What is a data fabric and what is it used for?
Data management in large enterprises has never been easy. But with the boom of digital technologies and tools, enterprises have created exponentially more data and it has become increasingly fragmented across disparate applications in the organization. Over time, new data management practices have emerged for managing these complex data issues, including data warehouses, data lakes, and data mesh—but for most modern businesses with complex data structures, they’re just not enough.
While all try to solve the challenges of joining data across disparate sources, they each have their own shortcomings for managing data efficiently, from increased or shifted technical debt to long and costly data migrations to reduced data integrity and data security concerns. In order to overcome these enterprise data management challenges, what many organizations need is a data fabric.
Data fabric also plays a key role in a modern process automation (or hyperautomation) platform that optimizes complex business processes end to end. That’s crucial as you seek to scale automation across an enterprise and achieve holistic improvement, not just isolated wins.
Data fabric definition
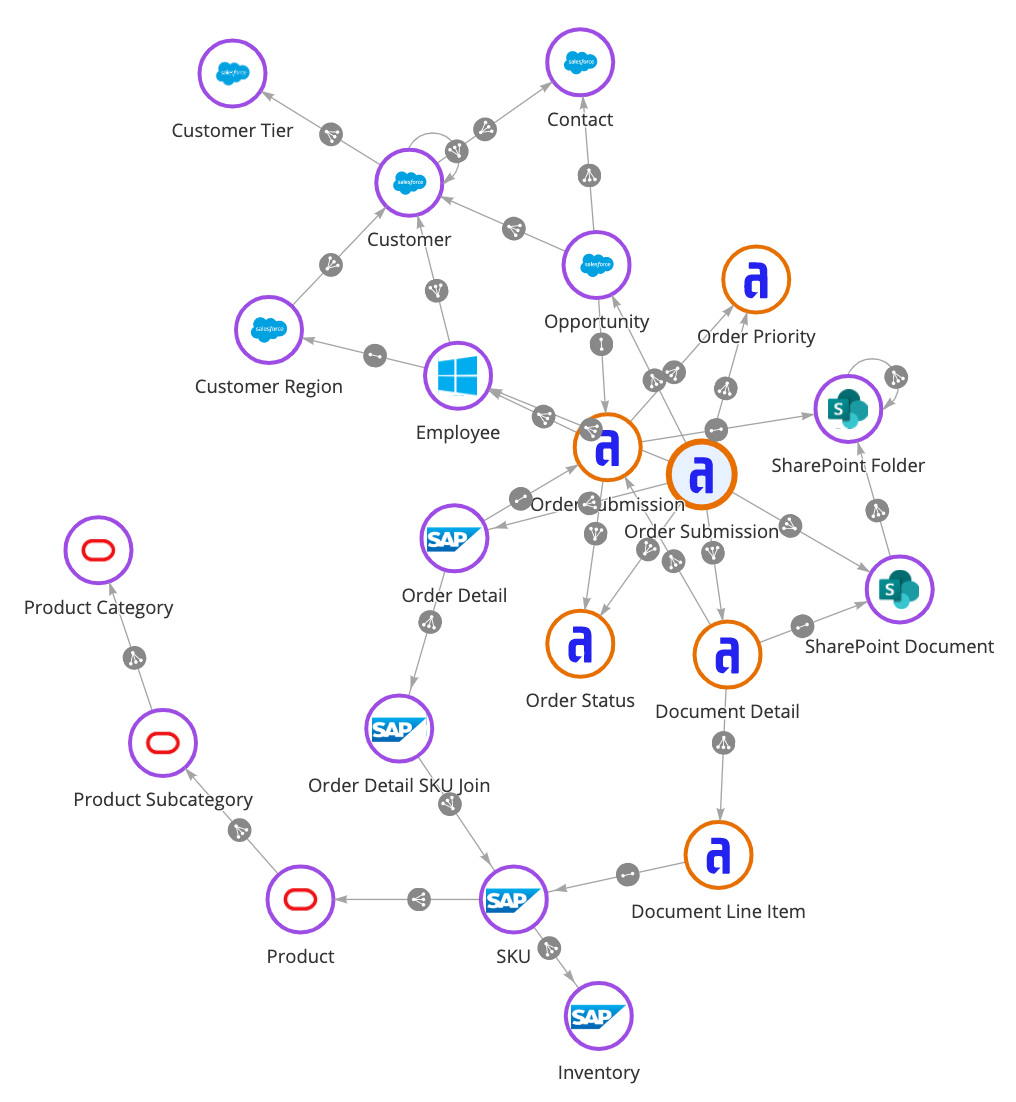
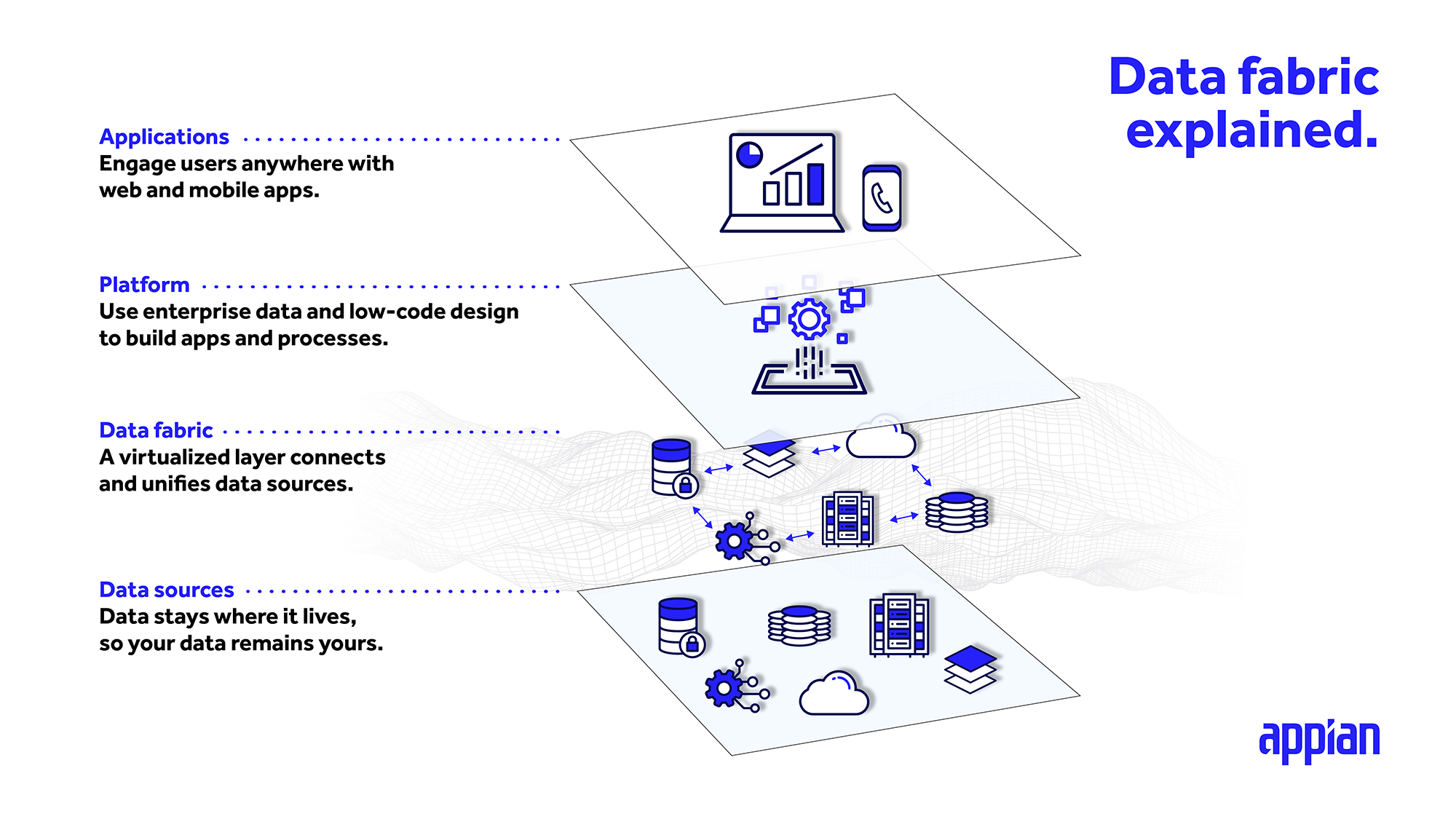
Let’s define data fabric: It’s an architecture layer and tool set that connects data across disparate systems and creates a unified view. It is a virtualized data layer. That means you don’t need to migrate data from where it currently lives, say in a database, Enterprise Resource Planning (ERP), or Customer Relationship Management (CRM) application. The data may be on-premise, in a cloud service, or in multi-cloud environments. With a data fabric approach, you can combine business data in entirely new ways, with particular benefit for digital transformation work. It’s a concept Gartner calls “composable design.” That’s one reason Gartner named data fabric its top strategic technology trend for 2022.
While data warehouses focus on collecting data, data fabric connects it.
Data fabric eliminates time-intensive and costly data migrations, with consistent capabilities that connect data directly from wherever it lives, giving you the ability to spin up applications and dramatically reducing the time to insight for business leaders. That’s critical for digital transformation work that demands speed and agility to give your organization a competitive edge. Data fabric also provides a simplified data modeling experience that democratizes data analysis, giving access not only to skilled data engineers and developers but also to line-of-business employees who need data-driven insights to reach their business objectives faster.
Organizations everywhere are using a data fabric approach to expand data access and create a single, secure, and complete view of data across their enterprises. That in turn drives digital innovation and better business decisions.
[ Want to learn more about how to solve your data silo problems and speed up innovation? Get the eBook: The Data Fabric Advantage. ]
How does a data fabric work?
One of the primary benefits of a data fabric is that you can leave the data where it currently sits today and access it just as easily as if it were living locally in your applications. Through an integrated layer that sits on top of systems and data sets, data fabrics centralize your data in one spot for you to access, relate, and extend. You might also think of data fabric as an abstraction layer for managing your data.
This integrated data layer connects directly to each source, letting you access data in real time and create, read, update, and delete (CRUD) pieces of data from wherever you’re leveraging it.
Whether it’s a CRM or ERP application, or even a homegrown relational database management system, enterprise data fabric architecture can weave together disparate sources into a single, unified data model for use across multiple applications.
[ Want a shareable PDF of this whole article? Download it now. ]
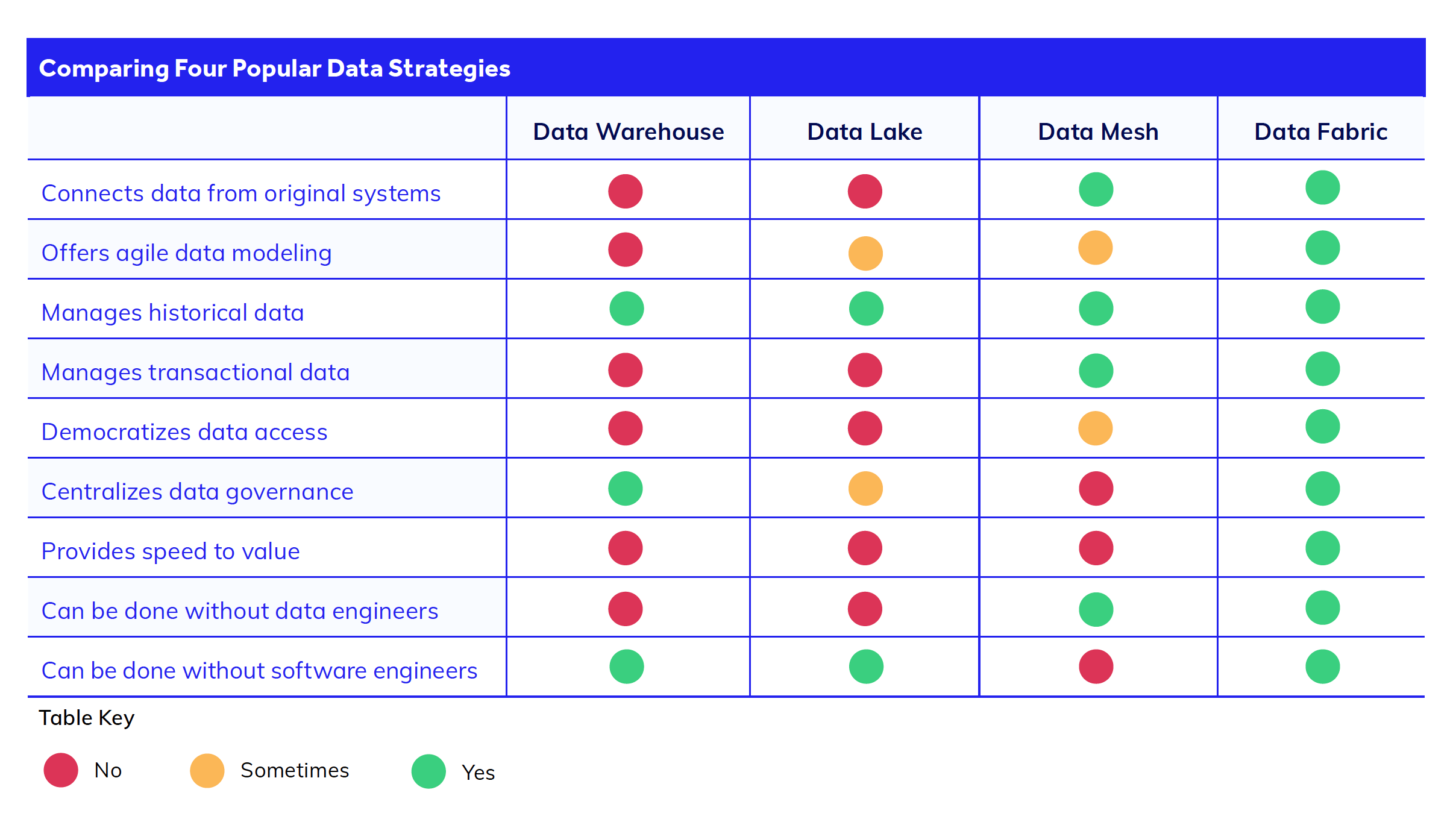
Data lake vs. data mesh vs. data fabric: What’s the difference?
Data management terminology quickly gets confusing, so let’s demystify some terms that may seem similar to data fabric but, in reality, have crucial differences.
Data lake.
A data lake is distinctly different from data fabric. Like a data warehouse, a data lake’s primary goal is only to collect data in a single repository—not connect it. Data lakes are used for large sets of unstructured data, whereas data warehouses are used for structured data.
With a data lake, you must lift all the data out of each system and load it all into one new system (the lake). The data sits in the lake until you do transformation and analysis work at a later date. A data lake suits analytical work, but doesn’t support transactional systems that require real-time data, such as CRM applications.
One key challenge with using data lakes for data management is that shifting the data out of a siloed system and into the lake means additional development time and development costs. For example, developers can’t spin up a new application until the data from the lake is cleaned up and migrated for them to use. The development maintenance and upkeep of this data lake tacks on additional technical debt to engineering teams over time.
Data mesh.
In contrast, data fabric and data mesh design architectures take a different approach. Both focus on connecting directly to the data sources vs. extracting all of your data. As we have discussed above, this allows you to access real-time data and avoid timely and costly migration projects.
However, data mesh and data fabric solve this data connection problem differently. Data mesh uses complex API integrations across microservices to stitch together systems across the enterprise. So with data mesh, while you avoid a lot of data engineering work, you trade it for additional software development efforts dealing with the APIs.
Data fabric.
What makes data fabric unique is its ability to create a virtualized data layer on top of data sets, removing the need for the complex API and coding work that a data mesh or data lake requires. This gives teams added speed and agility to do data analysis, data modeling, and digital transformation work.
[ Read our related article: Data fabric vs. data mesh vs. data lake.]
Why use a data fabric? Why is it important?
A data fabric architecture lets you quickly connect data across enterprise silos. But many data management and integrated tools out there claim to do this. So why use a data fabric, specifically?
A key benefit of using a data fabric is that it covers both transactional and analytical systems.
As noted earlier, transactional data is living data: it’s changing to support live systems such as case management applications, CRM software, and other applications where data needs to be updated regularly to support the real-time operations of a business. Analytical data is historical data. It is a view into the past—unchanging, immutable.
Other data management architectures like data warehouses and data lakes only support analytical data. When data changes, or is “mutable,” you begin to see cracks in these architectural strategies, as they can only provide you with the static data that was extracted from individual systems. This leads to data latency and impacts the usefulness of the data in your application. These other data architectures also still require a ton of developers to extract, transform, and load in data so that it can be used.
Conversely, a data fabric thrives in situations where data is constantly changing, such as applications that involve partner data-sharing. Because the data is virtualized and connected directly to the source systems, you can easily read/write to those systems. No migration work is required. Your team gains real-time data for real-time insights into your organization. This single source of data then can give you a complete view of your business—a holy grail that many teams have chased for years in search of better business outcomes.
What is a data fabric used for? Real-world examples.
What does a data fabric look like in real life? Data fabric technology can be used across an entire organization for many different use cases, as they can connect a wide range of data sets. Let’s look at just a couple of examples of how an organization would utilize a data fabric to connect disparate data sources across the enterprise to improve visibility and efficiency.
Data fabric in service request management.
Many enterprises have a business unit that deals with maintenance and services to their products (machines, utilities, etc.) In order to streamline efficiency, they need an application to manage all aspects of the request process, so the business unit looks to build a service request management application.
But typically the data they need to access, update, and take action on is spread out across the organization. The parts inventory lives in an ERP system, the customer’s equipment lives in a homegrown relational database, and the customer information sits in their CRM, for example.
In order to properly handle these service requests, the business needs to connect all three of their disparate systems. Migrating them into a single bucket would take too much time and effort, not to mention this data is changing and would be stale by the time it got to the business users.
Instead, the organization uses a data fabric architecture to connect directly to each system while leaving the data in its current place. This breaks down silos and minimizes the data design work needed. The result is real time data and operational insights throughout your service request application, where users can read and write directly to each source as if it were local data.
Data fabric in vendor onboarding.
Many organizations have to manage the process of onboarding vendors, whether they are contracted workers, materials suppliers, etc. In this example, let's say an organization wants to manage the granting of intellectual property (IP) to third parties based on their contracts with the organization.
This will require merging data across brand intellectual property stores, contract information, and CRM data. You’d also need to keep it up-to-date as users take their associated actions. And in this case, you would definitely need to secure certain intellectual property, depending on what the third party’s contract provides them.
A data fabric platform connects all three of these sources to let you access real-time information and secure your data across multiple systems of record with row-level security. This lets you reference your CRM to determine if certain rows of data in your IP database should be visible to the contractor. That’s the power of building a data fabric.
What are the business benefits of data fabrics?
What are the business benefits of utilizing a data fabric in your enterprise data architecture strategy? Top data fabric benefits include improved speed and agility, democratization of data modeling, more actionable business insights, and centralized data management for improved security and compliance.
And no data migration equals faster application development. That’s a key difference between data fabrics and data warehouses or data lakes. Particularly at times of competitive disruption or economic recession, every business leader wants speed and flexibility. You can get even more value from a data fabric architecture by combining it with no-code data modeling tools that have record-level security.
Without a rigid architecture, data fabric lets you easily change and update your organization’s data models over time. Because a virtual data layer sits on top of the data, you don’t need to do complex maintenance work and can quickly add, delete, and relate sources together as business needs change. And you can easily reuse pieces of work across workflows and applications, which means developers can leverage existing work to avoid duplicate efforts and gain speed.
According to Gartner’s Top 10 Data and Analytics Trends for 2021, Gartner found that data fabric reduces time for integration design by 30%, deployment by 30%, and maintenance by 70% because the technology designs draw on the ability to use, reuse, and combine different data integration styles.
A data fabric’s power to connect disparate data sets—without hordes of database specialists—means valuable data no longer hides in silos. Data fabric gives you a complete view of the data in your business, allowing your teams to make better, data-driven decisions.
Data fabric’s centralized approach also delivers benefits on security and compliance risks. With a data fabric, IT gains a centralized picture showing who can view, update, and delete specific data sets. As organizations democratize data access, sharing more data both inside the organization and outside with customers and partners, data fabric gives IT teams confidence they have a governed, secure data architecture. That’s important as regulatory demands continue to increase.
For all these reasons, businesses can harness the power of data fabric to drive new speed, better decisions, and ultimately, digital innovation.
[ Want to learn more on how a data fabric can transform your organizations data management strategies? Watch the on-demand webinar. ]
How data fabric fits into process automation strategy.
As some enterprises have already learned the hard way, automation success requires a strong data architecture. If you have data hiding in silos and systems that don’t communicate well, you may be able to automate pieces of a process, but you can’t automate the whole process end to end. That’s one reason why data fabric is a must-have capability in a process automation platform.
Process automation refers to tools that help enterprises automate and improve entire business processes, such as managing the customer lifecycle in banking, optimizing supply chain operations, or speeding up insurance underwriting. These intricate, lengthy processes involve multiple people, departments, and systems, often including legacy technology. A process automation platform combines an array of technologies to do the work, including robotic process automation (RPA), intelligent document processing (IDP), workflow orchestration, artificial intelligence (AI), system integrations, and business rules. By the way, hyperautomation and process automation refer to this same set of technologies.
Data fabric brings important capabilities to a process automation platform, as it connects data sets across various systems, whether they’re on-premises or in the cloud. Look for a process automation platform that also provides low- or no-code connectors so you can link those systems (like CRM, ERP, and database applications) without building the connections from scratch. The final must-have piece in a platform is a workflow orchestration layer, which directs and smoothly passes workflows between software bots and humans.
For enterprises seeking speed and agility, a process automation platform with data fabric capabilities also improves resiliency and security as you tweak processes in response to changing business or regulatory demands. Keep these crucial factors in mind as you scale your automation efforts.