What Is Data Fabric?
What is a data fabric?
Let's define data fabric: It's an architecture layer and tool set that connects data across disparate systems to create a unified view.
This data virtualization layer enables you to access data without migrating it from where it lives whether in a data lake or data warehouse, relational database, enterprise resource planning (ERP) system like SAP, CRM like Salesforce, or SaaS application. The data may be on-premises, in a cloud computing service, or in hybrid cloud environments.
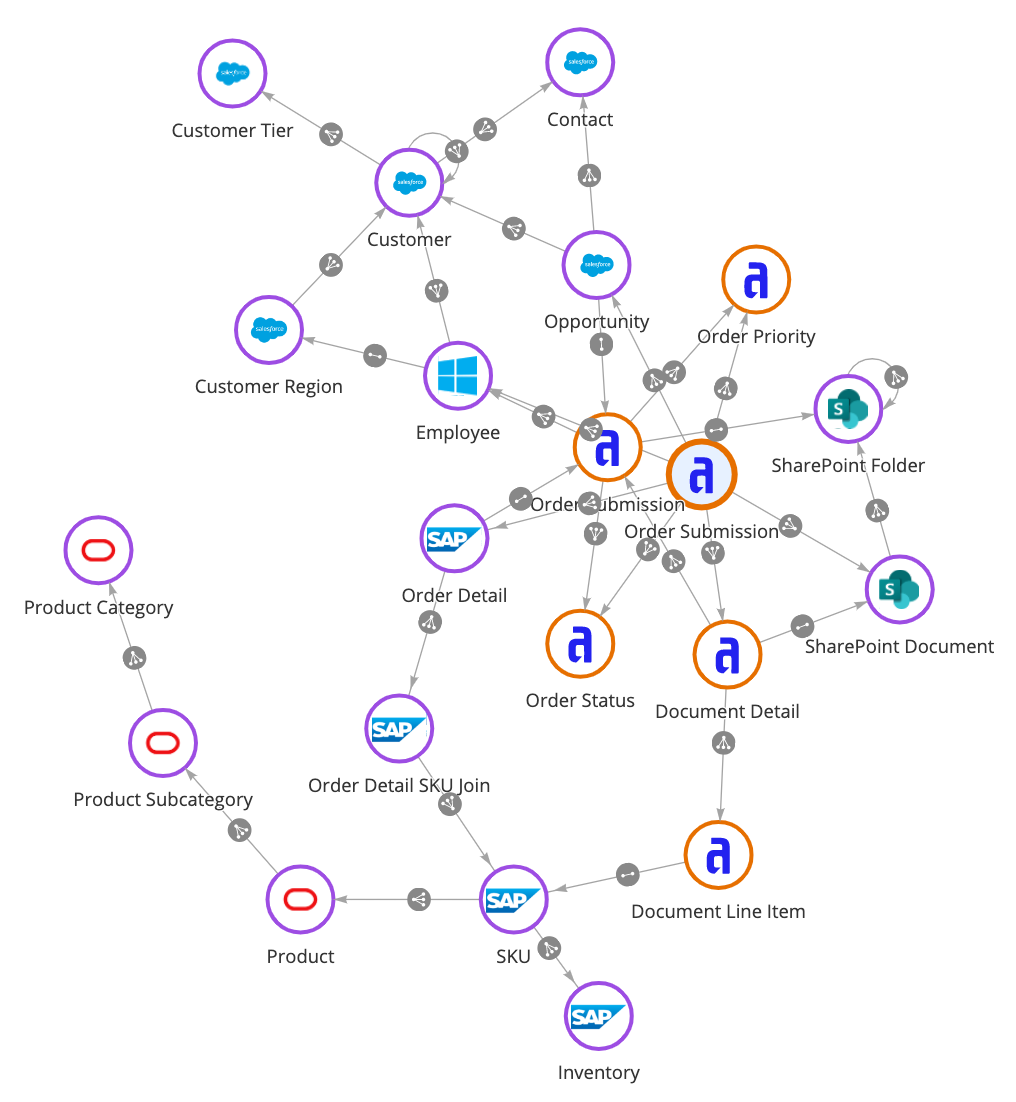
A data fabric allows for unified enterprise data integration across systems and locations.
What is a data fabric used for?
With the proliferation of digital technologies and tools like generative AI, enterprises have exponentially increased their data assets. And the data has become increasingly fragmented across different applications in the organization.
Over time, new data and metadata management practices have emerged for managing these complex data issues, including data warehouse, data lake, data lakehouse, and data mesh. But for most modern businesses with complex data structures, they each have their own shortcomings for managing data efficiently from increased or shifted technical debt to long and costly data migrations to reduced data integrity and data security concerns.
To overcome these enterprise-level data challenges, what many organizations need is a data fabric.
Data fabric plays a key role in a modern process automation platform that optimizes complex business processes end to end and enables AI transformation. That's crucial as you seek to scale automation and AI initiatives across the enterprise to achieve holistic improvement, not just isolated wins.
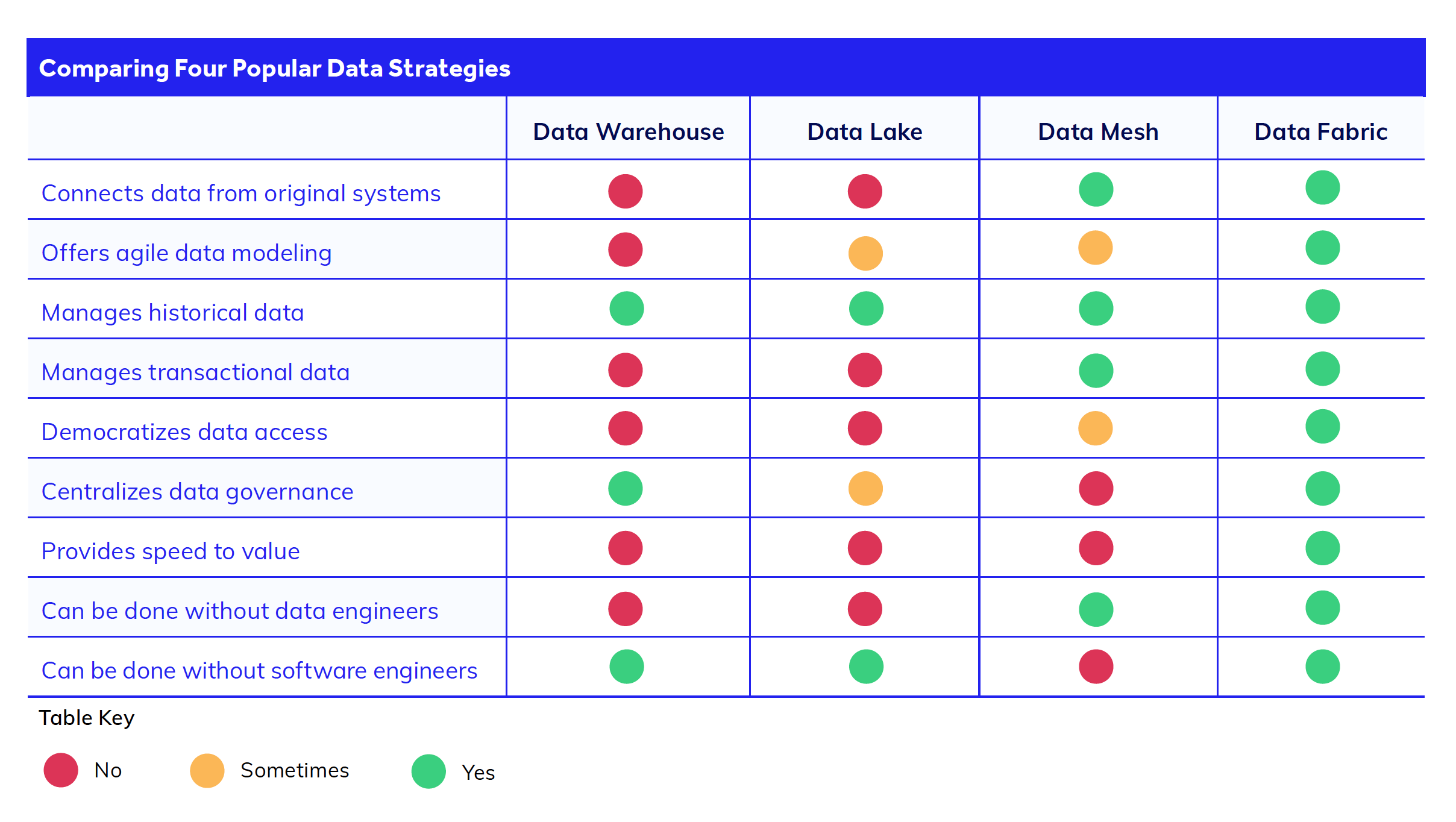
Data management approaches
There are multiple strategies for managing data across the enterprise. Let's take a closer look at some of these approaches to understand why they may not fulfill the needs of today's fast-moving enterprise.
Data warehouses, data lakes, and data lakehouses
The primary goal of these approaches is to collect data in a single repository, not connect it.
Data warehouses store structured operational data for analysis.
Data lakes store large sets of unstructured data, to be cleaned and analyzed later.
Data lakehouses combine the data lake's flexibility in type of data with the data warehouse's high-quality data components.
Data warehouses, lakes, and lakehouses are great tools for advanced analytics and operational reporting. But they still require you to lift all the data out of your siloed systems and load it into a new system (the warehouse, lake, or lakehouse). This means more maintenance and technical debt of yet another siloed system. Plus you need developers to complete the data integration piece using methods like extract, transform, load (ETL) so the data can be used, adding development time and costs.
While data warehouses focus on collecting data, data fabric connects it.
What's more, these repositories only suit analytical work that uses historical data. They don't support transactional systems that require real-time data integration, such as CRM applications.
Data mesh
In contrast, data fabric and data mesh take a different approach. They focus on connecting directly to the data sources rather than extracting all of your data. This allows you to access real-time data and avoid timely and costly migration projects.
However, data mesh and data fabric solve this data connection problem differently. Data mesh uses complex API integrations across microservices to stitch together systems across the enterprise. With data mesh, while you avoid a lot of data engineering work, you trade it for additional software development efforts dealing with the APIs.
Data fabric
What makes data fabric unique is its ability to create a data virtualization layer on top of your existing data sets, removing the need for the complex API and coding work that the alternatives require. This gives teams added speed and agility to do data analysis, data modeling, and digital transformation work rather than spending time on data ecosystem development.

How does a data fabric work?
One of the primary benefits of a data fabric is that you can leave your data assets where they currently sit today and access them just as easily as if they were living locally in your applications. Through an integrated layer that sits on top of systems and data sets, data fabrics virtually centralize your data in one spot for you to access, relate, and extend. You might also think of data fabric as an abstraction layer for managing your data.
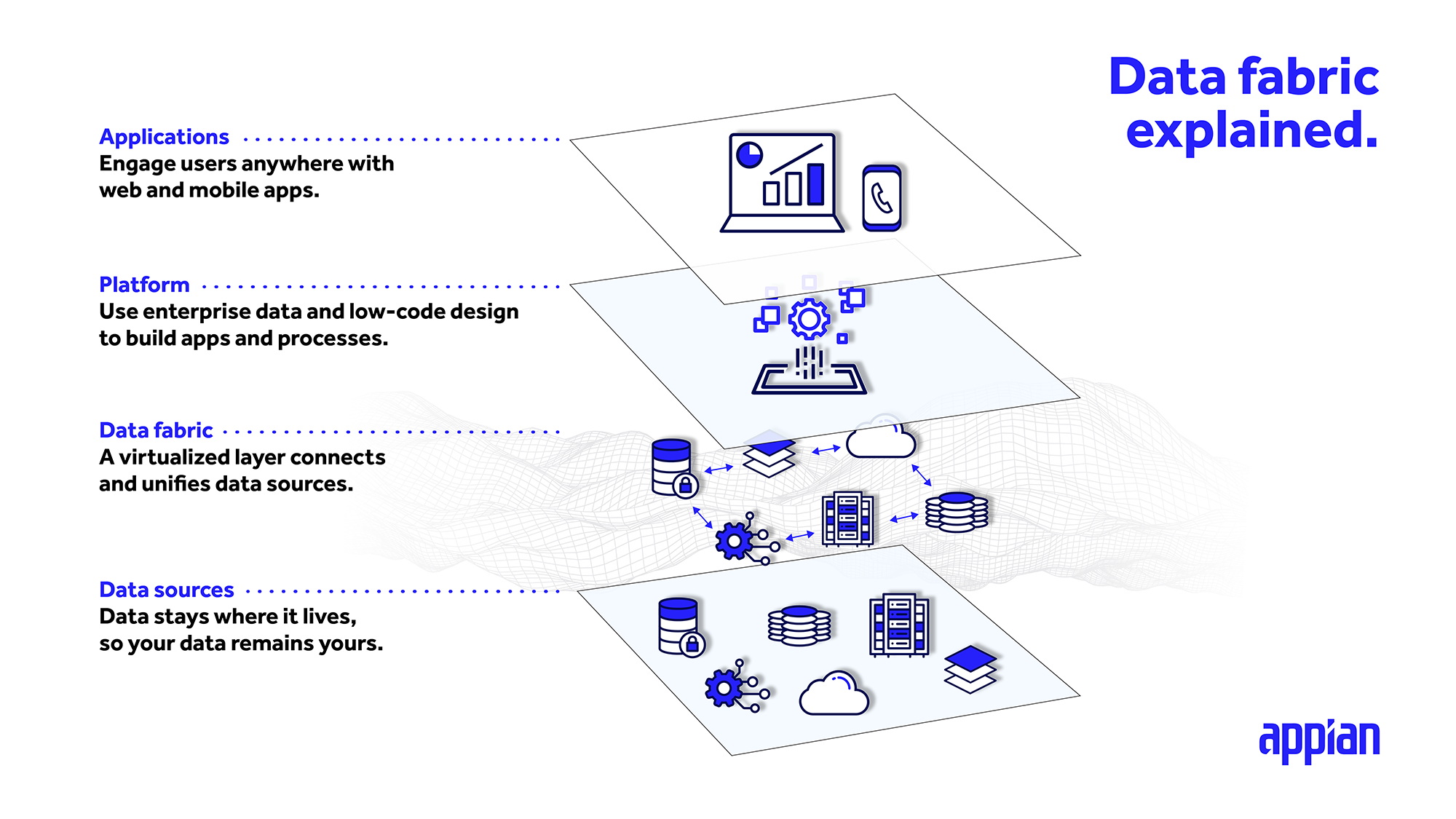
This integrated data layer connects directly to each source, letting you access data in real time. You can create, read, update, and delete (CRUD) pieces of data from wherever you're leveraging it.
Whether it's a CRM or ERP application, or even a homegrown relational database management system, enterprise data fabric architecture can weave together disparate sources into a single, unified data model for use across multiple applications.
Why use a data fabric? Why is it important?
A data fabric architecture lets you quickly connect data across enterprise silos. But many data management and integrated tools out there claim to do this. So why use a data fabric, specifically?
A key benefit of using a data fabric is that it covers both transactional and analytical systems.
A data fabric thrives in situations where data is constantly changing, such as applications that involve partner data-sharing. Because this data virtualization connects directly to source systems, you can easily read and write to those systems. No migration work or data movement is required. Your team gains real-time data for real-time intelligence into your organization. This single source of data gives you a complete view of your business—a holy grail that organizations have chased for years in search of better business outcomes.
Benefits of a data fabric
Here are some of the top benefits of using a data fabric:
De-silos your data by creating a secure connection for disparate data sets without requiring hordes of database specialists or ETL scenarios.
Improves business intelligence and decision-making by giving users a complete view of data, which also provides a better user experience.
Reduces development time and costs by connecting data directly from where it lives, eliminating time-intensive and costly data migrations.
Increases agility by letting you easily change and update your organization's data models with less complex maintenance. You can quickly add, delete, and relate sources together as business needs change.
Provides a simplified data modeling experience that democratizes data analysis, giving access not only to skilled data engineers and developers but also to line-of-business employees who need accurate business intelligence to reach their objectives faster.
Reduces security and compliance risks by giving IT a centralized picture showing who can view, update, and delete specific data sets.
Accelerates artificial intelligence (AI) adoption. AI and generative AI models are only as good as the data feeding them. A data fabric provides a unified, real-time source of truth that is essential for training models and grounding generative AI responses (using retrieval-augmented generation). This ensures your AI output is accurate, governed, and free from hallucinations caused by stale or siloed data.
According to Gartner®, data fabric reduces time for integration design by 30%, deployment by 30%, and maintenance by 70% because the technology designs draw on the ability to use, reuse, and combine different data integration styles.
For all these reasons, businesses can harness the power of data fabric to gain the competitive edge. It drives speed, better decisions, AI initiatives, and ultimately, digital innovation.

What does data fabric look like in real life?
Data fabric technology can be used across an entire organization for many different use cases, as they can connect a wide range of data sets. Let's look at just a couple of examples of how an organization would use this technology to create well-managed data pipelines from sources across the enterprise to improve visibility and efficiency.
Data fabric in service request management
Many enterprises have a business unit that deals with maintenance and service to their products (machines, utilities, etc.) To streamline efficiency, they need an application to manage all aspects of the request process, so the business unit looks to build a service request management application.
But typically the data they need to access, update, and take action on is spread out across the organization. The parts inventory lives in an ERP system, the customer's equipment lives in a homegrown relational database, and the customer information sits in their CRM, for example.
In order to properly handle these service requests, the business needs to connect all three of their disparate systems. Migrating them into a single bucket would take too much time and effort. Plus this data is constantly changing so it would be stale by the time it got to the business users.
Instead, the organization uses a data fabric architecture to connect directly to each system while leaving the data in its current place. This breaks down silos and minimizes the data design work needed. The result is real-time data and operational insights in your service request application, where users can read and write directly to each data source as if it were local.
Data fabric in vendor onboarding
Many organizations have to manage the process of onboarding vendors, whether they are contracted workers, materials suppliers, etc. In this example, let's say an organization wants to manage the granting of intellectual property (IP) to third parties based on their contracts with the organization.
This will require merging data across brand intellectual property stores, contract information, and CRM data. You'll also need to keep it up-to-date as users take their respective actions. And in this case, you would definitely need to secure certain intellectual property, depending on what the third party's contract provides them.
A data fabric platform connects all three of these sources so you can access real-time information and secure your data across multiple systems of record with row-level security. This lets you reference your CRM to determine if certain rows of data in your IP database should be visible to the contractor. That's the power of building a data fabric.
How data fabric fits into a process automation strategy
Automation success requires a strong data architecture. If you have data hiding in silos and systems that don't communicate well, you may be able to automate pieces of a process, but you can't automate the whole process end to end. That's one reason why data fabric is a must-have capability in a process automation platform.
Process automation refers to tools that help enterprises automate and improve entire business processes, such as managing the customer lifecycle in banking, optimizing supply chain operations, and speeding up insurance underwriting. These intricate, lengthy processes involve multiple people, departments, and systems, often including legacy technology. A process automation platform combines an array of technologies to do the work, including robotic process automation (RPA), intelligent document processing (IDP), workflow orchestration, AI, system integrations, and business rules.
Data fabric brings important capabilities to a process automation platform, as it connects data sets across various systems, whether they're on-premises, in cloud systems, or in hybrid environments. Look for a process automation platform that also provides low- or no-code connectors so you can link those systems (like CRM, ERP, and database applications) without building the connections from scratch. The last must-have piece in a platform is a workflow orchestration layer, which directs and smoothly passes workflows between software bots and humans.
For enterprises seeking speed and agility, a process automation platform with data fabric capabilities also improves resiliency and security as you tweak processes in response to changing business or regulatory demands. Keep these crucial factors in mind as you scale your automation efforts.
Finally, a data fabric is the prerequisite for scaling AI and generative AI effectively. AI models rely on good data. By unifying data from across the enterprise into a single virtual layer, a data fabric ensures that your AI has secure access to the complete, real-time intelligence and context that it needs to function accurately. The right platform can combine these technologies so you can embed private AI directly into workflows, confident that the outputs are grounded in real business data and that data remains secure.