Was ist Data Fabric?
Im Folgenden erfahren Sie, wie Data Fabrics funktionieren, warum sie wichtig sind, was der Unterschied zwischen Data Fabric, Data Mesh und Data Lakes ist, sowie Beispiele aus der Praxis und geschäftliche Vorteile.
Was ist eine Data Fabric und wofür wird sie verwendet?
Die Datenverwaltung in großen Unternehmen war noch nie einfach. Doch mit dem Aufschwung digitaler Technologien und Tools haben Unternehmen exponentiell mehr Daten erzeugt, die zunehmend über verschiedene Anwendungen im Unternehmen verteilt sind. Im Laufe der Zeit sind neue Datenverwaltungspraktiken für die Verwaltung dieser komplexen Datenprobleme entstanden, darunter Data Warehouses, Data Lakes und Data Mesh – aber für die meisten modernen Unternehmen mit komplexen Datenstrukturen sind sie einfach nicht ausreichend.
Sie alle versuchen zwar, die Herausforderungen bei der Zusammenführung von Daten aus unterschiedlichen Quellen zu bewältigen, haben aber jeweils ihre eigenen Schwächen bei der effizienten Verwaltung von Daten, von erhöhten oder verschobenen technischen Schulden über langwierige und kostspielige Datenmigrationen bis hin zu eingeschränkter Datenintegrität und Bedenken hinsichtlich der Datensicherheit. Um diese Herausforderungen bei der Verwaltung von Unternehmensdaten zu bewältigen, benötigen viele Unternehmen eine Data Fabric.
Data Fabric spielt auch eine Schlüsselrolle in einer modernen Prozessautomatisierungs- (oder Hyperautomatisierung) plattform, die komplexe Geschäftsprozesse von Anfang bis Ende optimiert. Dies ist von entscheidender Bedeutung, wenn Sie versuchen, die Automatisierung im gesamten Unternehmen zu skalieren und ganzheitliche Verbesserungen statt nur einzelner Erfolge zu erzielen.
Definition der Data Fabric
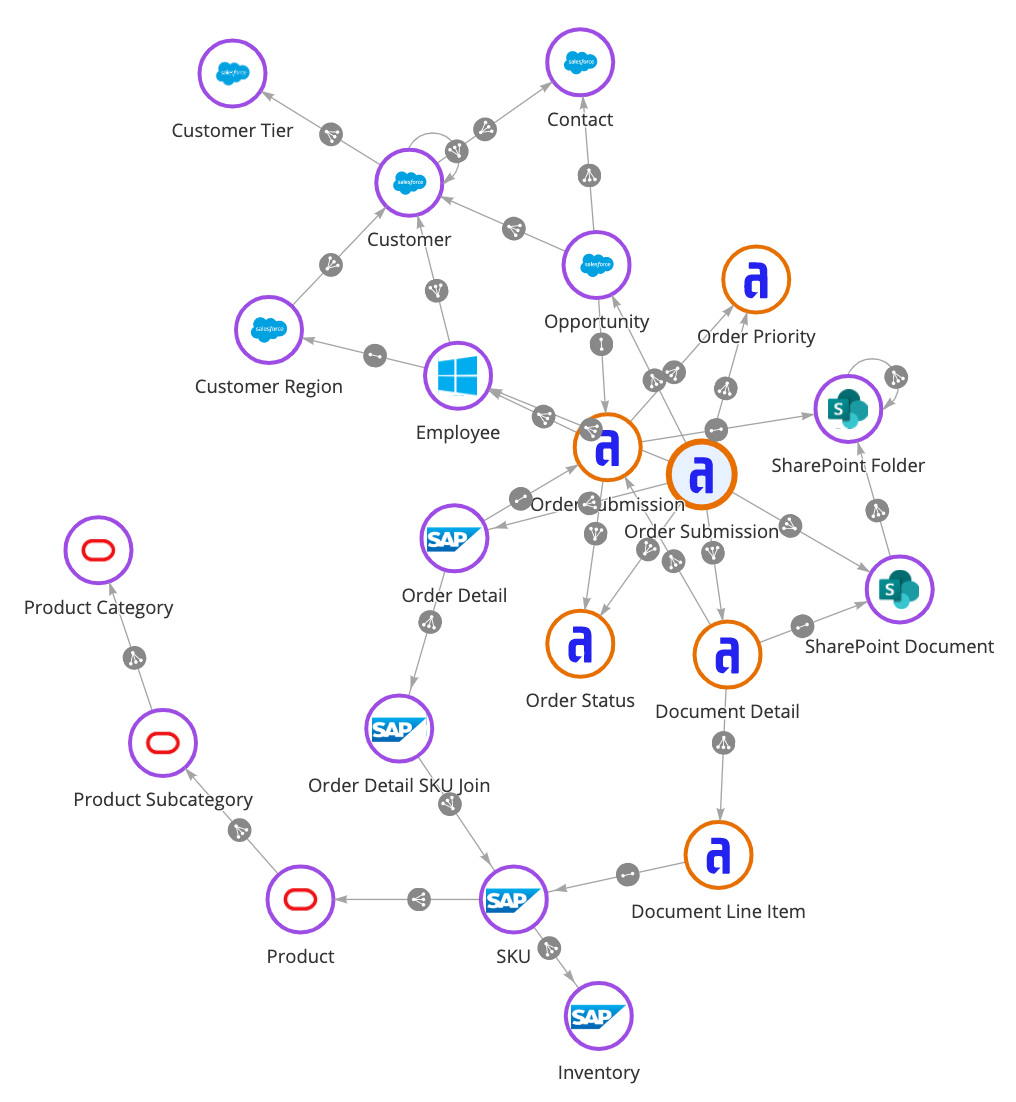
Definieren wir die Data Fabric: Es handelt sich um eine Architekturebene und ein Toolset, das Daten aus verschiedenen Systemen miteinander verbindet und eine einheitliche Ansicht schafft. Es handelt sich um eine virtualisierte Datenschicht. Das bedeutet, dass Sie die Daten nicht von dem Ort migrieren müssen, an dem sie sich derzeit befinden, z. B. in einer Datenbank, Enterprise Resource Planning (ERP)- oder Customer Relationship Management (CRM)-Anwendung. Die Daten können On-Premise, in einem Cloud-Dienst oder in Multi-Cloud-Umgebungen gespeichert sein. Mit einer Data-Fabric-Architecture können Sie Geschäftsdaten auf völlig neue Art und Weise kombinieren, was insbesondere für digitale Transformation von Vorteil ist. Dieses Konzept nennt Gartner „Composable Design“. Das ist einer der Gründe, warum Gartner Data Fabric zum wichtigsten strategischen Technologietrend für 2022 erklärt hat.
Während sich Data Warehouses auf das Sammeln von Daten konzentrieren, verbindet Data Fabric die Daten.
Data Fabric macht zeit- und kostenintensive Datenmigrationen überflüssig und bietet konsistente Funktionen, die Daten direkt dort verbinden, wo sie sich befinden. So können Sie Anwendungen sofort in Betrieb nehmen und die Zeit bis zur Gewinnung von Einblicke für Führungskräfte drastisch verkürzen. Das ist entscheidend für die digitale Transformation, die Schnelligkeit und Agilität erfordert, um Ihrem Unternehmen einen Wettbewerbsvorteil zu verschaffen. Data Fabric bietet außerdem eine vereinfachte Datenmodellierung, die die Datenanalyse demokratisiert und nicht nur qualifizierten Dateningenieuren und -entwicklern, sondern auch den Mitarbeitern der Geschäftsebene, die datengestützte Erkenntnisse benötigen, um ihre Geschäftsziele schneller zu erreichen, den Zugang ermöglicht.
Unternehmen in aller Welt nutzen einen Data-Fabric-Ansatz, um den Datenzugriff zu erweitern und eine einheitliche, sichere und vollständige Sicht auf die Daten in ihrem Unternehmen zu schaffen. Dies wiederum fördert digitale Innovationen und bessere Geschäftsentscheidungen.
[ Möchten Sie mehr darüber erfahren, wie Sie Ihre Probleme mit Datensilos lösen und Innovationen voranbringen können? Lesen Sie unser e-Book: Der Vorteil einer Data Fabric. ]
Wie funktioniert eine Data Fabric?
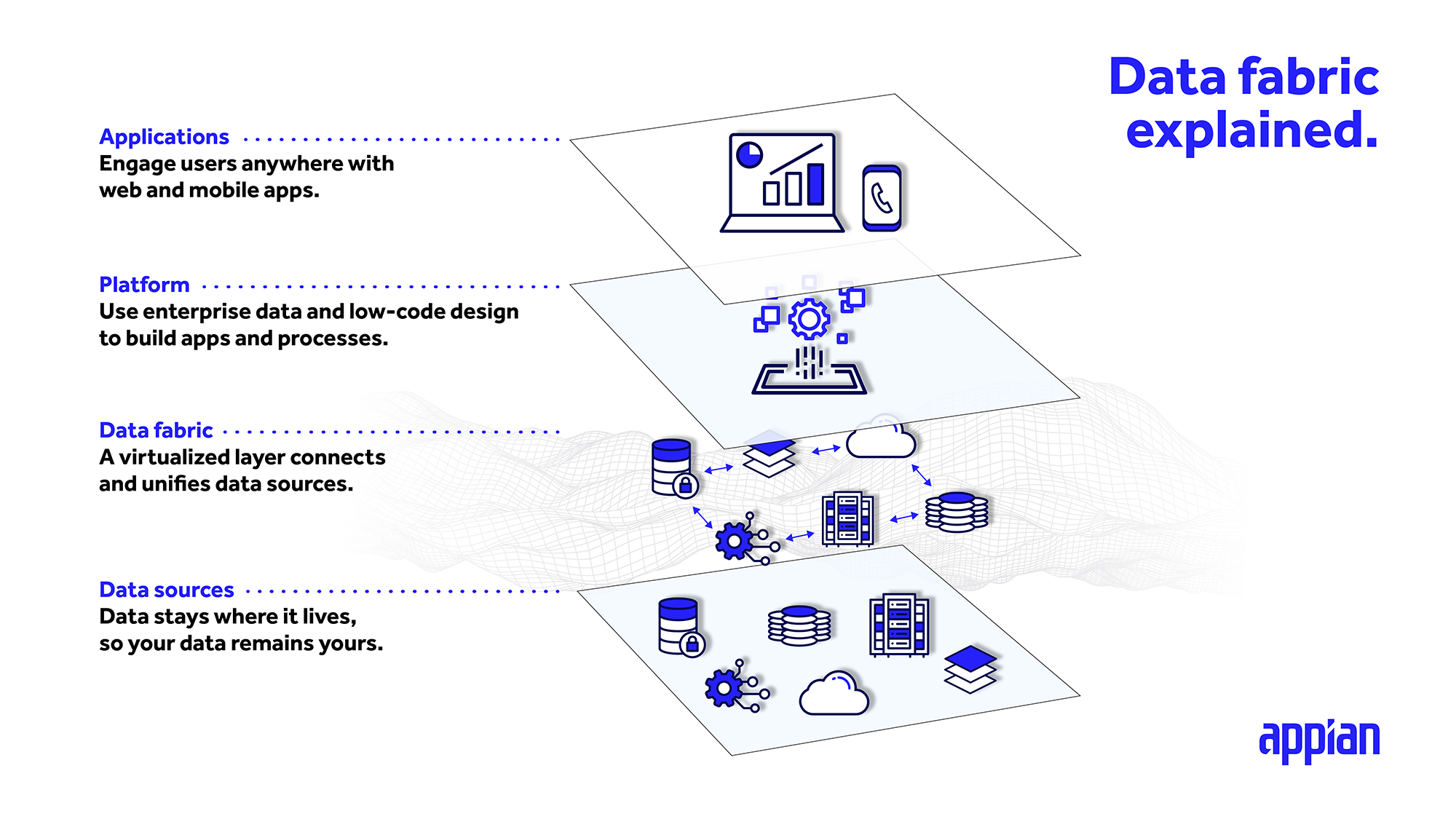
Einer der Hauptvorteile einer Data Fabric besteht darin, dass Sie die Daten dort belassen können, wo sie sich derzeit befinden, und auf sie genauso einfach zugreifen können, als ob sie lokal in Ihren Anwendungen vorhanden wären. Durch eine integrierte Schicht, die auf Systemen und Datensätzen aufsetzt, zentralisieren Data Fabrics Ihre Daten an einer Stelle, auf die Sie zugreifen, sie in Beziehung setzen und erweitern können. Sie können sich die Data Fabric auch als Abstraktionsschicht für die Verwaltung Ihrer Daten vorstellen.
Diese integrierte Datenebene stellt eine direkte Verbindung zu den einzelnen Quellen her, sodass Sie in Echtzeit auf die Daten zugreifen und Daten erstellen, lesen, aktualisieren und löschen (CRUD) können, unabhängig davon, wo Sie die Daten nutzen.
Unabhängig davon, ob es sich um eine CRM- oder ERP-Anwendung oder sogar um ein selbst entwickeltes relationales Datenbankmanagementsystem handelt, kann die Enterprise Data Fabric-Architektur unterschiedliche Quellen zu einem einzigen, einheitlichen Datenmodell für die Verwendung in mehreren Anwendungen zusammenführen.
[ Möchten Sie eine PDF-Datei des gesamten Artikels herunterladen? Jetzt herunterladen. ]
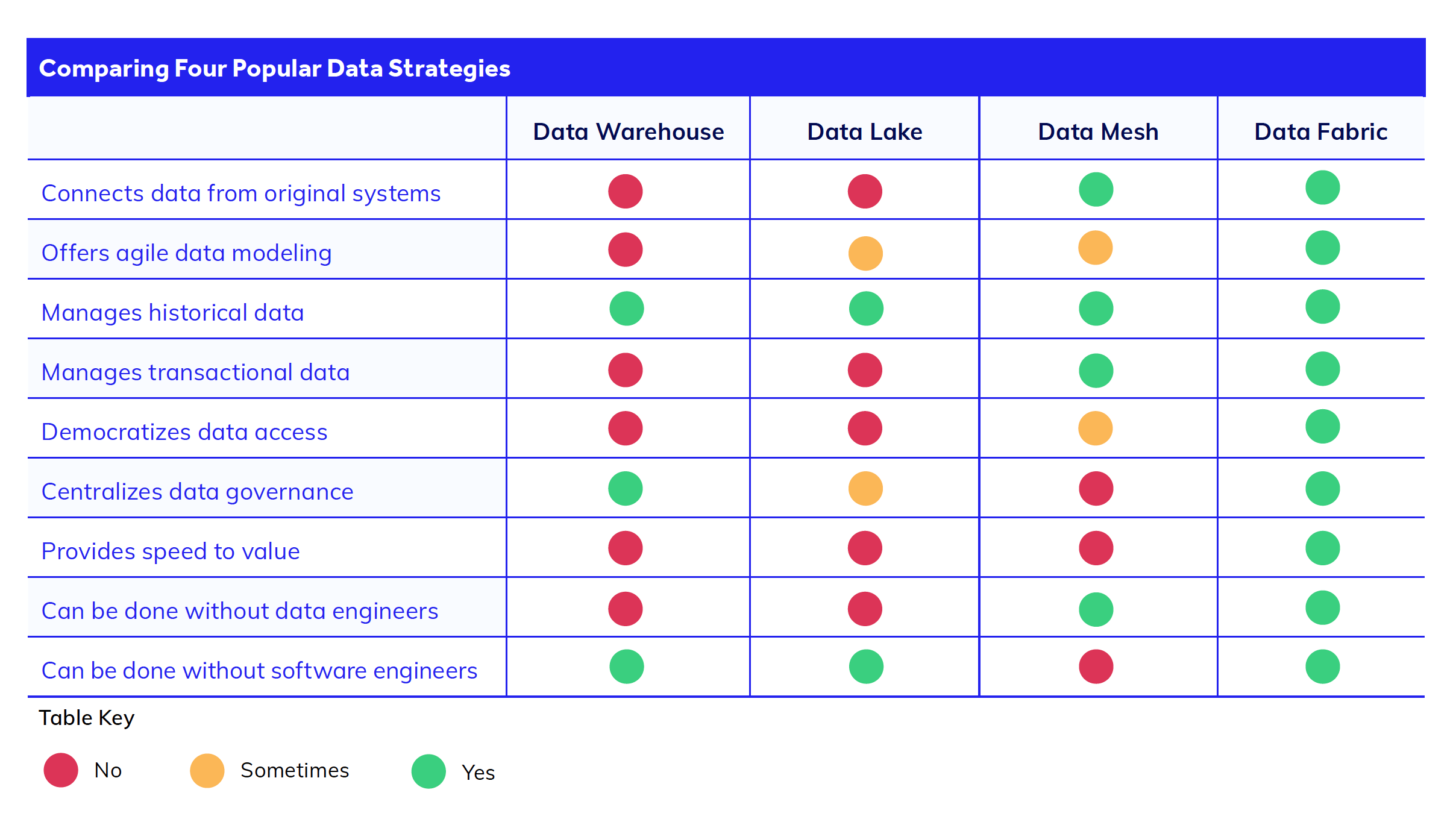
Data Lake vs. Data Mesh vs. Data Fabric. Was ist der Unterschied?
Die Terminologie des Datenmanagements kann schnell verwirrend werden. Lassen Sie uns daher einige Begriffe entmystifizieren, die auf den ersten Blick Ähnlichkeiten mit dem Begriff „Data Fabric“ aufweisen, in Wirklichkeit aber entscheidende Unterschiede haben.
Data Lake.
Ein Data Lake unterscheidet sich deutlich von einer Data Fabric. Wie ein Data Warehouse dient auch ein Data Lake in erster Linie dazu, Daten in einem einzigen Repository zu sammeln, nicht aber, sie zu verbinden. Data Lakes werden für große Mengen an unstrukturierten Daten verwendet, während Data Warehouses für strukturierte Daten eingesetzt werden.
Bei einem Data Lake müssen Sie alle Daten aus den einzelnen Systemen herausnehmen und in ein neues System (den Lake) laden. Die Daten verbleiben im Lake, bis Sie zu einem späteren Zeitpunkt Transformations- und Analysearbeiten durchführen. Ein Data Lake eignet sich für analytische Arbeit, unterstützt aber keine transaktionalen Systeme, die Echtzeitdaten benötigen, wie z. B. CRM-Anwendungen.
Eine der größten Herausforderungen bei der Verwendung von Data Lakes für die Datenverwaltung besteht darin, dass die Verlagerung der Daten aus einem isolierten System in den Lake zusätzliche Entwicklungszeit und -kosten bedeutet. So können Entwickler beispielsweise erst dann eine neue Anwendung starten, wenn die Daten aus dem Lake bereinigt und migriert sind, damit sie verwendet werden können. Die Entwicklungs- und Wartungsarbeiten an diesem Data Lake belasten die Entwicklerteams im Laufe der Zeit mit zusätzlichen technischen Schulden.
Data Mesh.
Im Gegensatz dazu verfolgen Data-Fabric- und Data-Mesh-Design-Architekturen einen anderen Ansatz. Bei beiden liegt der Schwerpunkt auf der direkten Verbindung zu den Datenquellen und nicht auf der Extraktion aller Ihrer Daten. Wie bereits erwähnt, können Sie so auf Echtzeitdaten zugreifen und zeit- und kostenintensive Migrationsprojekte vermeiden.
Data Mesh und Data Fabric lösen dieses Problem der Datenverbindung jedoch unterschiedlich. Data Mesh nutzt komplexe API-Integrationen über Microservices hinweg, um Systeme im gesamten Unternehmen miteinander zu verknüpfen. Bei der Datenverflechtung vermeiden Sie zwar viel Arbeit bei der Datentechnik, aber Sie tauschen sie gegen zusätzlichen Aufwand bei der Softwareentwicklung für die APIs.
Data Fabric.
Das Einzigartige an Data Fabric ist die Fähigkeit, eine virtualisierte Datenschicht über dem Datensatz zu erstellen, wodurch die komplexen API- und Kodierungsarbeiten, die für ein Data Mesh oder einen Data Lake erforderlich sind, entfallen. So können Teams Datenanalysen, Datenmodellierung und digitale Transformation schneller und flexibler durchführen.
[ Lesen Sie unseren entsprechenden Artikel: Data Fabric vs. Data Mesh vs. Data Lake.]
Warum eine Data Fabric verwenden? Und warum ist sie wichtig?
Mit einer Data-Fabric-Architecture können Sie Daten schnell über Unternehmenssilos hinweg verbinden. Aber viele Datenverwaltungs- und integrierte Tools auf dem Markt behaupten, dies zu können. Warum also ausgerechnet eine Data Fabric verwenden?
Ein wichtiges Unterscheidungsmerkmal dabei ist, dass eine Data Fabric sowohl transaktionelle als auch analytische Systeme abdeckt.
Wie bereits erwähnt, handelt es sich bei Transaktionsdaten um lebende Daten: Sie ändern sich, um lebende Systeme wie Case-Management-Anwendungen, CRM-Software und andere Anwendungen zu unterstützen, bei denen die Daten regelmäßig aktualisiert werden müssen, um den Echtzeitbetrieb eines Unternehmens zu unterstützen. Analytische Daten sind historische Daten. Sie sind ein Blick in die Vergangenheit – unveränderlich, starr.
Andere Datenverwaltungsarchitekturen wie Data Warehouses und Data Lakes unterstützen nur analytische Daten. Wenn sich Daten ändern oder „veränderlich“ sind, zeigen sich Risse in diesen Architekturstrategien, da sie nur statische Daten liefern können, die aus einzelnen Systemen extrahiert wurden. Dies führt zu Datenlatenz und beeinträchtigt den Nutzen der Daten in Ihrer Anwendung. Auch diese anderen Datenarchitekturen erfordern immer noch eine Menge Entwickler, um Daten zu extrahieren, umzuwandeln und zu laden, damit sie verwendet werden können.
Umgekehrt gedeiht eine Data Fabric in Situationen, in denen sich die Daten ständig ändern, wie z. B. bei Anwendungen, die die gemeinsame Nutzung von Partnerdaten beinhalten. Da die Daten virtualisiert und direkt mit den Quellsystemen verbunden sind, können Sie problemlos auf diesen Systemen lesen und schreiben. Es sind keine Migrationsarbeiten erforderlich. Ihr Team erhält Echtzeitdaten für Echtzeiteinblicke in Ihr Unternehmen. Diese einzige Datenquelle kann Ihnen dann einen vollständigen Überblick über Ihr Unternehmen verschaffen – ein heiliger Gral, den viele Teams seit Jahren auf der Suche nach besseren Geschäftsergebnissen verfolgt haben.
Wofür wird eine Data Fabric genutzt? Beispiele aus der Praxis.
Wie sieht eine Data Fabric im wirklichen Leben aus? Die Data Fabric-Technology kann in einem gesamten Unternehmen für viele verschiedene Anwendungsfälle eingesetzt werden, da sie eine Vielzahl von Datensätzen miteinander verbinden kann. Sehen wir uns nur einige Beispiele dafür an, wie ein Unternehmen eine Data Fabric nutzen kann, um unterschiedliche Datenquellen im gesamten Unternehmen zu verbinden und so die Transparenz und Effizienz zu verbessern.
Data Fabric in der Verwaltung von Serviceanfragen.
Viele Unternehmen haben einen Geschäftsbereich, der sich mit der Wartung und den Dienstleistungen für ihre Produkte (Maschinen, Versorgungseinrichtungen usw.) befasst. Um die Effizienz zu steigern, wird eine Anwendung benötigt, mit der alle Aspekte des Anfrageprozesses verwaltet werden können. Daher sucht die Geschäftseinheit nach einer Anwendung zur Verwaltung von Serviceanfragen.
Die Daten, auf die sie zugreifen, die sie aktualisieren und für die sie Maßnahmen ergreifen müssen, sind jedoch in der Regel über das gesamte Unternehmen verstreut. Das Ersatzteillager befindet sich in einem ERP-System, die Geräte des Kunden in einer selbst entwickelten relationalen Datenbank und die Kundeninformationen befinden sich beispielsweise in ihrem CRM.
Um diese Serviceanfragen ordnungsgemäß bearbeiten zu können, muss das Unternehmen alle drei unterschiedlichen Systeme miteinander verbinden. Die Migration dieser Daten in einen einzigen Bucket würde zu viel Zeit und Mühe kosten, ganz abgesehen davon, dass sich diese Daten ständig ändern und veraltet wären, bis sie bei den Geschäftsanwendern ankämen.
Stattdessen nutzt das Unternehmen eine Data-Fabric-Architecture, um eine direkte Verbindung zu jedem System herzustellen, während die Daten an ihrem aktuellen Ort verbleiben. Dadurch werden Silos aufgebrochen und der Aufwand für die Datengestaltung minimiert. Das Ergebnis sind Echtzeitdaten und betriebliche Einblicke in Ihrer gesamten Serviceanforderungsanwendung, wobei die Benutzer jede Quelle direkt lesen und beschreiben können, als handelte es sich um lokale Daten.
Data Fabric beim Onboarding von Lieferanten.
Viele Unternehmen müssen den Prozess des Onboarding von Zulieferern verwalten, unabhängig davon, ob es sich um Vertragsarbeiter, Materiallieferanten usw. handelt. In diesem Beispiel möchte ein Unternehmen die Gewährung von geistigem Eigentum (IP) an Dritte auf der Grundlage ihrer Verträge mit dem Unternehmen verwalten.
Dies erfordert die Zusammenführung von Daten aus den Speichern für geistiges Eigentum von Marken, Vertragsinformationen und CRM-Daten. Sie müssen sie auch auf dem neuesten Stand halten, wenn die Benutzer ihre entsprechenden Aktionen durchführen. Und in diesem Fall müssten Sie auf jeden Fall bestimmte geistige Eigentumsrechte sichern, je nachdem, was der Vertrag des Dritten vorsieht.
Eine Data-Fabric-Plattform verbindet alle drei Quellen, damit Sie in Echtzeit auf Informationen zugreifen und Ihre Daten über mehrere Datensysteme hinweg mit Sicherheit auf Zeilenebene schützen können. Damit können Sie auf Ihr CRM verweisen, um zu bestimmen, ob bestimmte Datenzeilen in Ihrer IP-Datenbank für den Auftragnehmer sichtbar sein sollen. Das ist die Stärke des Aufbaus einer Data Fabric.
Was sind die geschäftlichen Vorteile von Data Fabrics?
Welche geschäftlichen Vorteile ergeben sich aus der Verwendung einer Data Fabric in Ihrer Strategie für die Unternehmensdatenarchitektur? Zu den wichtigsten Vorteilen von Data Fabric gehören eine höhere Geschwindigkeit und Flexibilität, die Demokratisierung der Datenmodellierung, bessere Geschäftseinblicke und eine zentralisierte Datenverwaltung für mehr Sicherheit und Compliance.
Und keine Datenmigration bedeutet eine schnellere Anwendungsentwicklung. Das ist ein wesentlicher Unterschied zwischen Data Fabrics und Data Warehouses oder Data Lakes. Vor allem in Zeiten von Wettbewerbsverzerrungen oder wirtschaftlicher Rezession wünscht sich jeder Unternehmensleiter Schnelligkeit und Flexibilität. Sie können sogar noch mehr Nutzen aus einer Data Fabric-Architektur ziehen, indem Sie sie mit No-Code Datenmodellierungstools kombinieren, die über Sicherheit auf Datensatzebene verfügen.
Ohne starre Architektur können Sie mit Data Fabric die Datenmodelle Ihres Unternehmens im Laufe der Zeit problemlos ändern und aktualisieren. Da eine virtuelle Datenschicht über den Daten liegt, müssen Sie keine komplexen Wartungsarbeiten durchführen und können Quellen schnell hinzufügen, löschen und miteinander in Beziehung setzen, wenn sich die Geschäftsanforderungen ändern. Außerdem lassen sich Teile der Arbeit problemlos in verschiedenen Workflows und Anwendungen wiederverwenden, so dass Entwickler bereits vorhandene Arbeit nutzen können, um Doppelarbeit zu vermeiden und die Geschwindigkeit zu erhöhen.
Laut Gartner's Top 10 Data and Analytics Trends for 2021 hat Gartner festgestellt, dass Data Fabric die Zeit für das Integrationsdesign um 30 %, die Bereitstellung um 30 % und die Wartung um 70 % reduziert, da die Technologie-Designs auf der Fähigkeit beruhen, verschiedene Datenintegrationsstile zu verwenden, wiederzuverwenden und zu kombinieren.
Die Fähigkeit einer Data Fabric, unterschiedliche Datensätze zu verbinden – ohne Horden von Datenbankspezialisten – bedeutet, dass wertvolle Daten nicht länger in Silos versteckt sind. Data Fabric gibt Ihnen einen vollständigen Überblick über die Daten in Ihrem Unternehmen und ermöglicht es Ihren Teams, bessere, datengestützte Entscheidungen zu treffen.
Der zentralisierte Ansatz von Data Fabric bietet auch Vorteile bei Sicherheits- und Compliance-Risiken. Mit einer Data Fabric erhält die IT-Abteilung einen zentralen Überblick darüber, wer bestimmte Datensätze anzeigen, aktualisieren und löschen kann. Da Unternehmen den Datenzugriff demokratisieren und immer mehr Daten sowohl innerhalb des Unternehmens als auch außerhalb mit Kunden und Partnern austauschen, gibt Data Fabric den IT-Teams die Gewissheit, dass sie über eine geregelte, sichere Datenarchitektur verfügen. Das ist wichtig, da die gesetzlichen Anforderungen weiter steigen.
Aus all diesen Gründen können Unternehmen die Leistungsfähigkeit von Data Fabric nutzen, um die Geschwindigkeit zu erhöhen, bessere Entscheidungen zu treffen und letztlich digitale Innovationen zu fördern.
[ Möchten Sie mehr darüber erfahren, wie eine Data Fabric die Datenverwaltungsstrategien Ihres Unternehmens verändern kann? On-Demand-Webinar ansehen. ]
Wie sich Data Fabric in die Prozessautomatisierungsstrategie einfügt.
Wie einige Unternehmen bereits auf die harte Tour gelernt haben, erfordert der Erfolg der Automatisierung eine starke Datenarchitektur. Wenn sich die Daten in Silos verstecken und die Systeme nicht gut miteinander kommunizieren, können Sie vielleicht Teile eines Prozesses automatisieren, aber nicht den gesamten Prozess von Anfang bis Ende. Das ist einer der Gründe, warum Data Fabric eine unverzichtbare Funktion in einer Prozessautomatisierungsplattform ist.
Die Prozessautomatisierung bezieht sich auf Tools, die Unternehmen dabei helfen, ganze Geschäftsprozesse zu automatisieren und zu verbessern, wie z. B. die Verwaltung des Kundenlebenszyklus im Bankwesen, die Optimierung der Lieferkettenabläufe oder die Beschleunigung des Underwritings bei Versicherungen. An diesen komplizierten, langwierigen Prozessen sind mehrere Personen, Abteilungen und Systeme beteiligt, häufig auch ältere Technologien. Eine Plattform zur Prozessautomatisierung kombiniert eine Reihe von Technologien, um die Arbeit zu erledigen, darunter robotergesteuerte Prozessautomatisierung (RPA), intelligente Dokumentenverarbeitung (IDP), Workflow-Orchestrierung, künstliche Intelligenz (KI), Systemintegrationen und Geschäftsregeln. Übrigens: Hyperautomatisierung und Prozessautomatisierung beziehen sich auf dieselbe Gruppe von Technologien.
Data Fabric bietet wichtige Funktionen für eine Prozessautomatisierungsplattform, da sie Datensätze über verschiedene Systeme hinweg verbindet, unabhängig davon, ob sie sich On-Premises oder in der Cloud befinden. Suchen Sie nach einer Prozessautomatisierungsplattform, die auch Low- oder No-Code-Konnektoren bietet, damit Sie diese Systeme (wie CRM-, ERP- und Datenbankanwendungen) miteinander verbinden können, ohne die Verbindungen von Grund auf neu erstellen zu müssen. Das letzte unverzichtbare Element einer Plattform ist eine Workflow-Orchestrierungsschicht, die die Arbeitsabläufe zwischen Software-Bots und Menschen steuert und reibungslos weiterleitet.
Für Unternehmen, die Schnelligkeit und Agilität anstreben, verbessert eine Prozessautomatisierungsplattform mit Data-Fabric-Funktionen auch die Ausfallsicherheit und die Sicherheit, wenn Sie Prozesse als Reaktion auf sich ändernde geschäftliche oder gesetzliche Anforderungen anpassen. Behalten Sie diese entscheidenden Faktoren im Hinterkopf, wenn Sie Ihre Automatisierungsbemühungen erweitern.