Qu’est-ce que la data fabric ?
Voici un aperçu du fonctionnement des data fabrics, de leur importance, de la différence entre data fabric, data mesh et data lakes, ainsi que des exemples concrets et des avantages pour l’entreprise.
Qu’est-ce qu’une data fabric et à quoi sert-elle ?
La gestion des données dans les grandes entreprises n’a jamais été facile. Mais avec l’essor des technologies et des outils numériques, les entreprises ont créé une quantité exponentielle de données et celles-ci sont devenues de plus en plus fragmentées entre les applications disparates de l’organisation. Au fil du temps, de nouvelles pratiques de gestion des données sont apparues pour gérer ces problèmes de données complexes, notamment les entrepôts de données, les lacs de données et les maillages de données, mais pour la plupart des entreprises modernes dotées de structures de données complexes, elles ne sont tout simplement pas suffisantes.
Bien qu’elles tentent toutes de résoudre les problèmes liés à l’intégration de données provenant de sources disparates, elles présentent chacune leurs propres lacunes en matière de gestion efficace des données, qu’il s’agisse de l’augmentation ou du déplacement de la dette technique, des migrations de données longues et coûteuses ou de la réduction de l’intégrité et de la sécurité des données. Pour surmonter ces défis de gestion des données d’entreprise, de nombreuses organisations ont besoin d’une hyperautomatisation des données (data fabric).
La data fabric joue également un rôle clé dans une plateforme moderne d’automatisation des processus (ou hyperautomatisation) qui optimise de bout en bout les processus métiers complexes. Cet aspect est crucial lorsque vous cherchez à étendre l’automatisation à l’ensemble de l’entreprise et à obtenir des améliorations globales, et pas seulement des gains isolés.
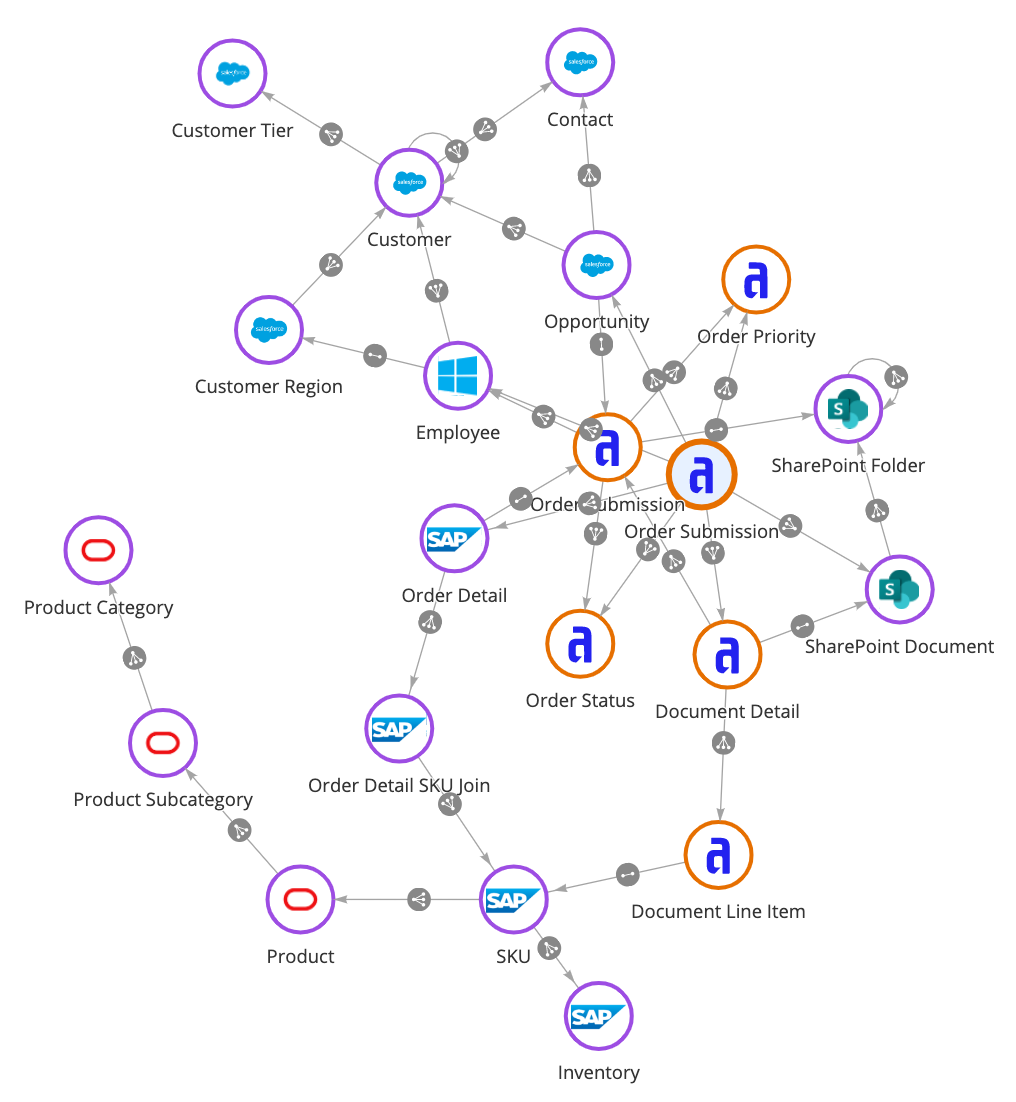
Définition de la data fabric
Définissons la data fabric : Il s’agit d’une couche d’architecture et d’un ensemble d’outils qui relient les données de systèmes disparates et créent une vue unifiée. Il s’agit d’une couche de données virtualisée. Cela signifie que vous n’avez pas besoin de migrer les données de l’endroit où elles se trouvent actuellement, par exemple dans une base de données, un progiciel de gestion intégré (ERP) ou une application de gestion de la relation client (CRM). Les données peuvent se trouver on-premise, dans un service cloud ou dans des environnements multi-cloud. Avec une approche de data fabric, vous pouvez combiner les données d’entreprise de manière entièrement nouvelle, avec un avantage particulier pour le travail de transformation numérique. C’est un concept que Gartner appelle « conception composable ». C’est l’une des raisons pour lesquelles Gartner a désigné la data fabric comme sa principale tendance technologique stratégique pour 2022.
Alors que les entrepôts de données se concentrent sur la collecte des données, la data fabric les connecte.
La data fabric élimine les migrations de données longues et coûteuses, avec des capacités cohérentes qui connectent les données directement où qu’elles vivent, vous donnant la possibilité de faire tourner les applications et réduisant considérablement le temps de perspective pour les chefs d’entreprise. C’est essentiel pour les travaux de transformation numérique qui exigent rapidité et agilité pour donner à votre organisation un avantage concurrentiel. La data fabric offre également une expérience de modélisation des données simplifiée qui démocratise l’analyse des données, en donnant accès non seulement aux ingénieurs et développeurs de données compétents, mais aussi aux employés opérationnels qui ont besoin de perspectives basées sur les données pour atteindre plus rapidement leurs objectifs commerciaux.
Partout, les organisations utilisent une approche de data fabric pour élargir l’accès aux données et créer une vue unique, sécurisée et complète des données dans l’ensemble de leur entreprise. Cette approche favorise l’innovation numérique et la prise de meilleures décisions.
[ Vous voulez découvrir comment résoudre vos problèmes de silos de données et accélérer l’innovation ? Accédez à l’eBook : L’avantage de la data fabric. ]
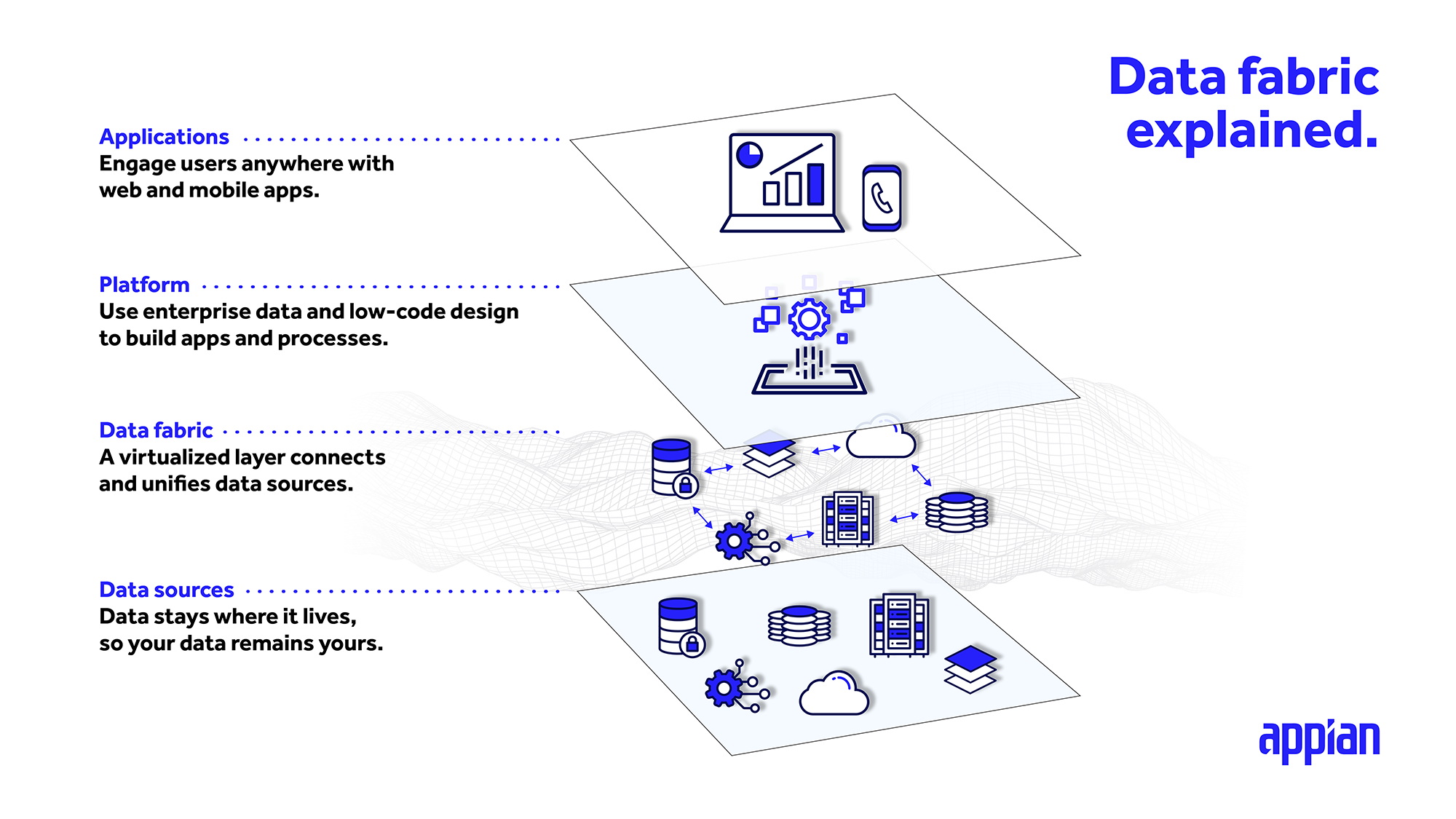
Comment fonctionne une data fabric ?
L’un des principaux avantages d’une data fabric est que vous pouvez laisser les données là où elles se trouvent actuellement et y accéder aussi facilement que si elles vivaient localement dans vos applications. Grâce à une couche intégrée qui s’appuie sur les systèmes et les ensembles de données, les data fabrics centralisent vos données en un seul endroit pour que vous puissiez y accéder, les relier et les étendre. Vous pouvez également considérer la data fabric comme une couche d’abstraction pour la gestion de vos données.
Cette couche de données intégrée se connecte directement à chaque source, ce qui vous permet d’accéder aux données en temps réel et de créer, lire, mettre à jour et supprimer (CRUD) des éléments de données, quel que soit l’endroit où vous les exploitez.
Qu’il s’agisse d’une application de gestion de la relation clients ou d’ERP, ou même d’un système de gestion de base de données relationnelle maison, l’architecture de data fabric d’entreprise peut rassembler des sources disparates en un modèle de données unique et unifié à utiliser dans plusieurs applications.
[ Vous voulez un PDF partageable de l’ensemble de cet article ? Téléchargez-le maintenant. ]
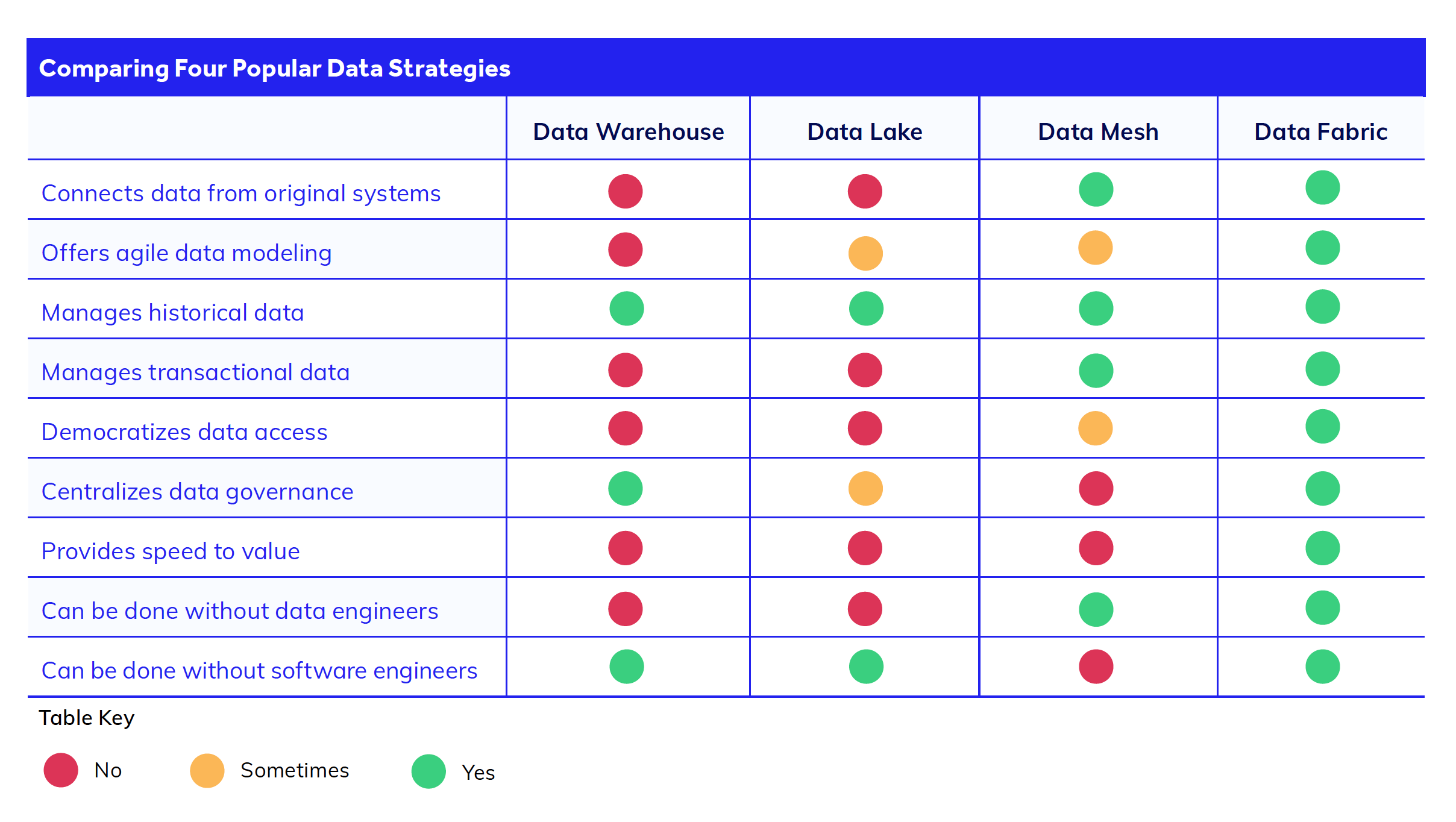
Data fabric, maillage de données et lac de données : quelle est la différence ?
La terminologie de la gestion des données prête rapidement à confusion, alors démystifions certains termes qui peuvent sembler similaires à la data fabric mais qui, en réalité, présentent des différences cruciales.
Lac de données
Un lac de données est nettement différent d’une data fabric. À l’instar d’un entrepôt de données, l’objectif premier d’un lac de données est de collecter des données dans un référentiel unique, et non de les connecter. Les lacs de données sont utilisés pour les grands ensembles de données non structurées, tandis que les entrepôts de données sont utilisés pour les données structurées.
Avec un lac de données, vous devez extraire toutes les données de chaque système et les charger dans un nouveau système (le lac). Les données restent dans le lac jusqu’à ce que vous fassiez le travail de transformation et d’analyse à une date ultérieure. Un lac de données convient au travail analytique, mais ne prend pas en charge les systèmes transactionnels qui nécessitent des données en temps réel, comme les applications de gestion de la relation clients.
L’une des principales difficultés liées à l’utilisation des lacs de données pour la gestion des données réside dans le fait que le transfert des données d’un système cloisonné vers le lac implique un temps et des coûts de développement supplémentaires. Par exemple, les développeurs ne peuvent pas lancer une nouvelle application tant que les données du lac n’ont pas été nettoyées et migrées pour qu’ils puissent les utiliser. Le développement, la maintenance et l’entretien de ce lac de données alourdissent la dette technique des équipes techniques au fil du temps.
Maillage de données.
En revanche, les architectures de conception de data fabric et de data mesh adoptent une approche différente. Toutes deux se concentrent sur la connexion directe aux sources de données plutôt que sur l’extraction de toutes vos données. Comme nous l’avons vu plus haut, cela vous permet d’accéder à des données en temps réel et d’éviter des projets de migration opportuns et coûteux.
Cependant, le data mesh et la data fabric résolvent différemment ce problème de connexion des données. Le maillage de données utilise des intégrations d’API complexes à travers des microservices pour relier les systèmes de l’entreprise. Ainsi, avec le maillage de données, si vous évitez une grande partie du travail d’ingénierie des données, vous l’échangez contre des efforts supplémentaires de développement de logiciels pour gérer les API.
Data fabric
Ce qui rend la data fabric unique, c’est sa capacité à créer une couche de données virtualisée au-dessus des ensembles de données, en supprimant le travail complexe d’API et de codage qu’exige un data mesh ou un data lake. Les équipes bénéficient ainsi d’une rapidité et d’une agilité accrues pour effectuer des analyses de données, des modélisations de données et des travaux de transformation numérique.
[ Lisez notre article connexe : Data fabric, maillage de données et lac de données.]
Pourquoi utiliser une data fabric ? Quelle est son importance ?
Une architecture data fabric vous permet de connecter rapidement les données entre les silos de l’entreprise. Mais de nombreux outils de gestion et d’intégration des données prétendent pouvoir le faire. Alors pourquoi utiliser une data fabric ?
L’un des principaux avantages de l’utilisation d’une data fabric est qu’elle couvre à la fois les systèmes transactionnels et analytiques.
Comme indiqué précédemment, les données transactionnelles sont des données vivantes : elles évoluent pour prendre en charge des systèmes vivants tels que les applications de case management, les logiciels de gestion de la relation clients et d’autres applications dans lesquelles les données doivent être mises à jour régulièrement pour prendre en charge les opérations en temps réel d’une entreprise. Les données analytiques sont des données historiques. Il s’agit d’une vue du passé, changeante et immuable.
Les autres architectures de gestion des données, telles que les entrepôts de données et les lacs de données, ne prennent en charge que les données analytiques. Lorsque les données changent, ou sont « mutables », ces stratégies architecturales commencent à se fissurer, car elles ne peuvent vous fournir que des données statiques extraites de systèmes individuels. Cela entraîne une latence des données et a un impact sur l’utilité des données dans votre application. Ces autres architectures de données requièrent également une multitude de développeurs pour extraire, transformer et charger les données afin qu’elles puissent être utilisées.
À l’inverse, une data fabric prospère dans les situations où les données changent constamment, comme dans les applications qui impliquent le partage de données entre partenaires. Les données étant virtualisées et connectées directement aux systèmes sources, vous pouvez facilement lire/écrire dans ces systèmes. Aucun travail de migration n’est nécessaire. Votre équipe obtient des données en temps réel pour des perspectives en temps réel sur votre organisation. Cette source unique de données peut alors vous donner une vue d’ensemble de votre entreprise - un but ultime que de nombreuses équipes poursuivent depuis des années à la recherche de meilleurs résultats commerciaux.
À quoi sert une data fabric ? Exemples concrets
À quoi ressemble une data fabric dans la vie réelle ? La technologie de data fabric peut être utilisée dans l’ensemble d’une organisation pour de nombreux cas d’usage différents, car elle permet de connecter un large éventail d’ensembles de données. Voyons quelques exemples de la manière dont une organisation peut utiliser une data fabric pour connecter des sources de données disparates dans l’ensemble de l’entreprise afin d’améliorer la visibilité et l’efficacité.
Data fabric dans la gestion des demandes de service
De nombreuses entreprises ont une unité commerciale qui s’occupe de la maintenance et des services pour leurs produits (machines, utilitaires, etc.) Afin de rationaliser l’efficacité, ils ont besoin d’une application pour gérer tous les aspects du processus de demande, l’unité métier cherche donc à créer une application de gestion des demandes de service.
Mais en général, les données auxquelles elle doit accéder, qu’elle doit mettre à jour et sur lesquelles elle doit agir sont dispersées dans l’ensemble de l’organisation. Le stock de pièces détachées se trouve dans un système ERP, l’équipement du client se trouve dans une base de données relationnelle maison et les informations sur le client se trouvent dans leur gestion de la relation clients, par exemple.
Pour traiter correctement ces demandes de service, l’entreprise doit connecter ces trois systèmes disparates. Les migrer dans une seule base de données prendrait trop de temps et d’efforts, sans compter que ces données changent et seraient périmées au moment où elles parviendraient aux utilisateurs professionnels.
Au lieu de cela, l’organisation utilise une architecture de data fabric pour se connecter directement à chaque système tout en laissant les données à leur place actuelle. Cela permet d’éliminer les silos et de minimiser le travail de conception des données nécessaire. Il en résulte des données en temps réel et des perspectives opérationnelles dans l’ensemble de votre application de demande de service, où les utilisateurs peuvent lire et écrire directement dans chaque source comme s’il s’agissait de données locales.
Data fabric dans l’intégration des fournisseurs
De nombreuses organisations doivent gérer le processus d’intégration des fournisseurs, qu’il s’agisse de travailleurs sous contrat, de fournisseurs de matériaux, etc. Dans cet exemple, disons qu’une organisation souhaite gérer l’octroi de la propriété intellectuelle (PI) à des tiers sur la base de leurs contrats avec l’organisation.
Pour ce faire, il faudra fusionner les données des magasins de propriété intellectuelle de la marque, les informations sur les contrats et les données de la gestion clients. Vous devrez également les tenir à jour au fur et à mesure que les utilisateurs effectueront les actions qui leur sont associées. Et dans ce cas, vous devrez certainement sécuriser certaines propriétés intellectuelles, en fonction de ce que le contrat du tiers prévoit.
Une plateforme de data fabric relie ces trois sources pour vous permettre d’accéder à des informations en temps réel et de sécuriser vos données sur plusieurs systèmes d’enregistrement avec une sécurité au niveau des lignes. Vous pouvez ainsi faire référence à votre gestion de la relation clients pour déterminer si certaines lignes de données de votre base de données IP doivent être visibles par le contractant. C’est là toute la puissance de la construction d’une data fabric.
Quels sont les avantages commerciaux des data fabrics ?
Quels sont les avantages de l’utilisation d’une data fabric dans votre stratégie d’architecture de données d’entreprise ? Les principaux avantages de la data fabric sont l’amélioration de la vitesse et de l’agilité, la démocratisation de la modélisation des données, des perspectives commerciales plus exploitables et la gestion centralisée des données pour une sécurité et une conformité accrues.
De plus, l’absence de migration des données permet d’accélérer le développement des applications. C’est une différence essentielle entre les data fabrics et les entrepôts de données ou les lacs de données. En particulier en période de perturbation de la concurrence ou de récession économique, tous les chefs d’entreprise veulent de la rapidité et de la flexibilité. Vous pouvez tirer encore plus de valeur d’une architecture de data fabric en l’associant à des outils de modélisation de données sans code qui offrent une sécurité au niveau de l’enregistrement.
Sans architecture rigide, la data fabric vous permet de modifier et d’actualiser facilement les modèles de données de votre organisation au fil du temps. Comme une couche de données virtuelles se trouve au-dessus des données, vous n’avez pas besoin d’effectuer des travaux de maintenance complexes et vous pouvez rapidement ajouter, supprimer et relier des sources entre elles en fonction de l’évolution des besoins de l’entreprise. De plus, vous pouvez facilement réutiliser des éléments de travail dans les workflows et les applications, ce qui signifie que les développeurs peuvent exploiter le travail existant pour éviter les doublons et gagner en rapidité.
Selon Gartner’s Top 10 Data and Analytics Trends for 2021, Gartner a constaté que la data fabric réduit le temps de conception de l’intégration de 30 %, le déploiement de 30 % et la maintenance de 70 %, car les conceptions technologiques s’appuient sur la capacité d’utiliser, de réutiliser et de combiner différents styles d’intégration de données.
La capacité d’une data fabric à relier des ensembles de données disparates - sans avoir recours à des hordes de spécialistes des bases de données - signifie que les données précieuses ne se cachent plus dans des silos. La data fabric vous offre une vue complète des données de votre entreprise, ce qui permet à vos équipes de prendre de meilleures décisions basées sur les données.
L’approche centralisée de la data fabric permet également de réduire les risques liés à la sécurité et à la conformité. Grâce à la data fabric, le service informatique dispose d’une image centralisée indiquant qui peut consulter, mettre à jour et supprimer des ensembles de données spécifiques. Alors que les organisations démocratisent l’accès aux données, en partageant davantage de données à l’intérieur de l’organisation et à l’extérieur avec les clients et les partenaires, la structure de données donne aux équipes informatiques l’assurance de disposer d’une architecture de données gouvernée et sécurisée. C’est important, car les exigences réglementaires ne cessent d’augmenter.
Pour toutes ces raisons, les entreprises peuvent exploiter la puissance de la data fabric pour favoriser une nouvelle vitesse, de meilleures décisions et, en fin de compte, l’innovation numérique.
[ Vous voulez en savoir plus sur la façon dont une data fabric peut transformer les stratégies de gestion des données de vos organisations ? Regardez le webinaire à la demande. ]
Comment la data fabric s’intègre dans la stratégie d’automatisation des processus.
Comme certaines entreprises l’ont déjà appris à leurs dépens, le succès de l’automatisation nécessite une architecture de données solide. Si les données se cachent dans des silos et que les systèmes ne communiquent pas bien, vous pourrez peut-être automatiser des parties d’un processus, mais vous ne pourrez pas automatiser l’ensemble du processus de A à Z. C’est l’une des raisons pour lesquelles la structure de données (data fabric) a été conçue pour répondre à ce besoin. C’est l’une des raisons pour lesquelles la data fabric est une fonctionnalité indispensable dans une plateforme d’automatisation des processus.
L’automatisation des processus fait référence aux outils qui aident les entreprises à automatiser et à améliorer des processus métiers entiers, tels que la gestion du cycle de vie du client dans le secteur bancaire, l’optimisation des opérations de la chaîne d’approvisionnement, ou l’accélération de la souscription d’assurance. Ces processus longs et complexes impliquent plusieurs personnes, services et systèmes, dont souvent des technologies anciennes. Une plateforme d’automatisation des processus combine un ensemble de technologies pour faire le travail, notamment l’automatisation des processus robotisés (RPA), le traitement intelligent des documents (IDP), l’orchestration des workflows, l’intelligence artificielle (IA), les intégrations de systèmes et les règles métier. D’ailleurs, hyperautomatisation et automatisation des processus font référence à ce même ensemble de technologies.
La data fabric apporte d’importantes capacités à une plateforme d’automatisation des processus, car elle connecte des ensembles de données à travers divers systèmes, qu’ils soient on premise ou dans le cloud. Recherchez une plateforme d’automatisation des processus qui propose également des connecteurs Low-Code ou sans code afin que vous puissiez relier ces systèmes (comme les applications de gestion de la relation clients, d’ERP et de base de données) sans avoir à créer les connexions à partir de zéro. Le dernier élément indispensable d’une plateforme est une couche d’orchestration du workflow, qui dirige et transmet en douceur les workflows entre robots logiciels et humains.
Pour les entreprises en quête de rapidité et d’agilité, une plateforme d’automatisation des processus dotée de capacités de data fabric améliore également la résilience et la sécurité lorsque vous modifiez les processus en réponse à l’évolution des exigences commerciales ou réglementaires. Gardez ces facteurs cruciaux à l’esprit lorsque vous développerez vos efforts d’automatisation.