Che cos’è il data fabric?
Ecco come funzionano i data fabric, perché sono importanti, la differenza tra data fabric, data mesh e data lake, oltre ad esempi reali e vantaggi aziendali.
Che cos'è un data fabric e a cosa serve?
La gestione dei dati nelle grandi aziende non è mai stata semplice. Tuttavia, con il boom delle tecnologie e degli strumenti digitali, le aziende hanno creato un numero esponenziale di dati, che sono diventati sempre più frammentati nelle diverse applicazioni dell'organizzazione. Nel corso del tempo sono emerse nuove pratiche di gestione dei dati per gestire questi problemi complessi, tra cui i data warehouse, i data lake ed i data mesh. Tuttavia, per la maggior parte delle aziende moderne con strutture complesse di dati questi non sono sufficienti.
Sebbene tutti cerchino di risolvere le sfide legate all'unione di dati provenienti da fonti diverse, ognuno di essi presenta i propri difetti nella gestione efficiente dei dati, dall'aumento o spostamento del debito tecnico a migrazioni di dati lunghe e costose, fino alla riduzione dell'integrità e della sicurezza dei dati. Per vincere queste sfide di gestione dei dati aziendali, molte organizzazioni hanno bisogno di un data fabric.
Il data fabric svolge inoltre un ruolo fondamentale in una moderna piattaforma di automazione dei processi (o hyperautomation) che ottimizza i complessi processi aziendali end-to-end. Questo è fondamentale quando si cerca di scalare l'automazione in tutta l'azienda e di ottenere un miglioramento globale invece di vittorie parziali.
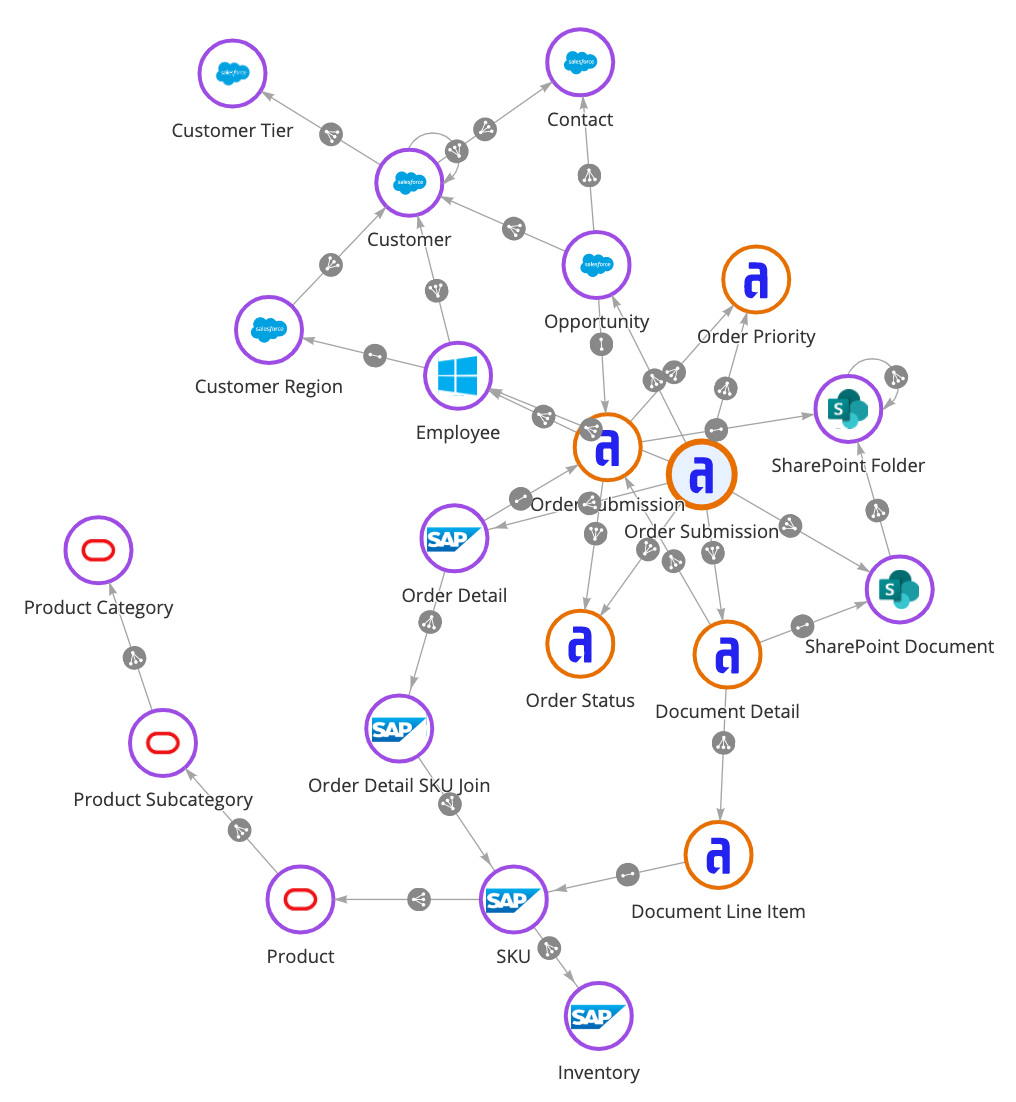
Definizione di data fabric
Definiamo il data fabric: si tratta di un livello di architettura e di un insieme di strumenti che collegano i dati tra sistemi diversi e creano una visione unificata. Si tratta di un livello di dati virtualizzato. Ciò significa che non è necessario migrare i dati dal luogo in cui si trovano attualmente, ad esempio un database, un'applicazione di Enterprise Resource Planning (ERP) o di Customer Relationship Management (CRM). I dati possono trovarsi on-premise, in un servizio cloud o in ambienti multi-cloud. Con un approccio di data fabric, è possibile combinare i dati aziendali in modi completamente nuovi, con particolari vantaggi per il lavoro di trasformazione digitale. È un concetto che Gartner chiama "composable design". Questo è uno dei motivi per cui Gartner ha indicato il data fabric come il principale trend tecnologico strategico per il 2022.
Mentre i data warehouse si concentrano sulla raccolta dei dati, il data fabric li collega.
Il data fabric elimina le migrazioni di dati costose e dispendiose in termini di tempo, grazie a funzionalità coerenti che collegano i dati direttamente dal luogo in cui si trovano, dando la possibilità di ruotare le applicazioni e riducendo drasticamente il tempo necessario per ottenere gli approfondimenti per i leader aziendali. Questo è fondamentale per il lavoro di trasformazione digitale che richiede velocità e agilità per dare alla vostra organizzazione un vantaggio competitivo. Il data fabric offre inoltre un'esperienza di modellazione dei dati semplificata che democratizza l'analisi dei dati, consentendo l'accesso non solo a ingegneri e sviluppatori di dati qualificati, ma anche ai dipendenti line-of-business che necessitano di approfondimenti basati sui dati per raggiungere più rapidamente gli obiettivi aziendali.
Le organizzazioni di tutto il mondo utilizzano un approccio di data fabric per ampliare l'accesso ai dati e creare una visione unica, sicura e completa dei dati in tutta l'azienda. Questo, a sua volta, spinge all'innovazione digitale e a decisioni aziendali migliori.
[ Vuoi saperne di più su come risolvere i problemi sui tuoi dati a compartimenti stagni e accelerare l’innovazione? Richiedi l’eBook: The Data Fabric Advantage. ]
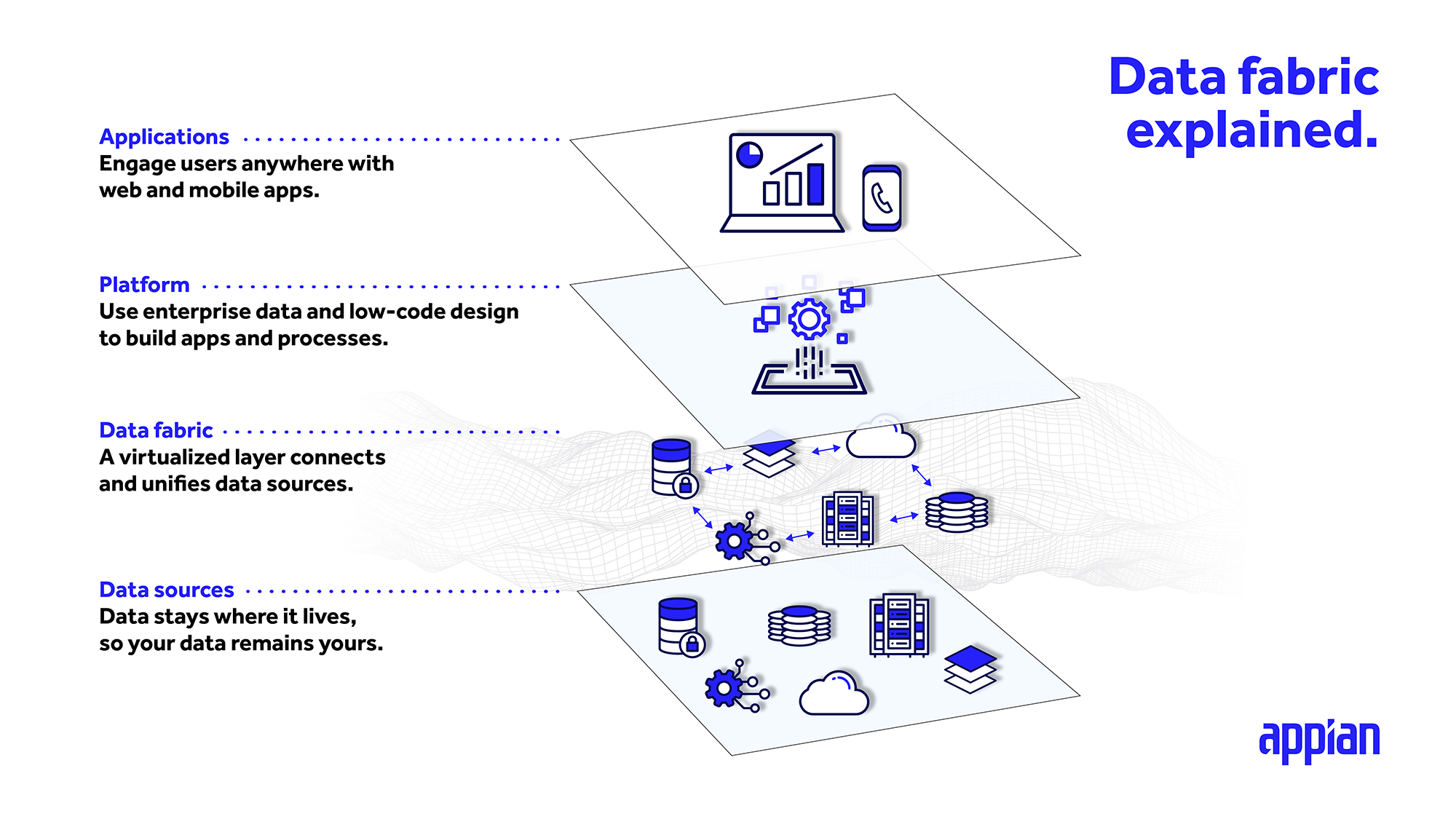
Come funziona un data fabric?
Uno dei principali vantaggi di un data fabric è la possibilità di lasciare i dati dove si trovano attualmente e di accedervi con la stessa facilità con cui si accede alle applicazioni locali. Grazie a un livello integrato che si colloca sopra i sistemi ed i set di dati, i data fabric centralizzano i vostri dati in un unico punto per consentirvi di accedervi, relazionarli ed estenderli. Si potrebbe anche pensare al data fabric come ad un livello di astrazione per la gestione dei dati.
Questo livello di dati integrato si collega direttamente a ciascuna fonte, consentendo di accedere ai dati in tempo reale e di creare, leggere, aggiornare e cancellare (CRUD) pezzi di dati da qualsiasi punto in cui li si utilizzi.
Che si tratti di un'applicazione CRM o ERP, o anche di un sistema di gestione di database relazionali sviluppato in casa, l'architettura enterprise data fabric può riunire fonti diverse in un unico modello di dati unificato da utilizzare in più applicazioni.
[ Vuoi un PDF condivisibile dell'intero articolo? Scaricalo ora. ]
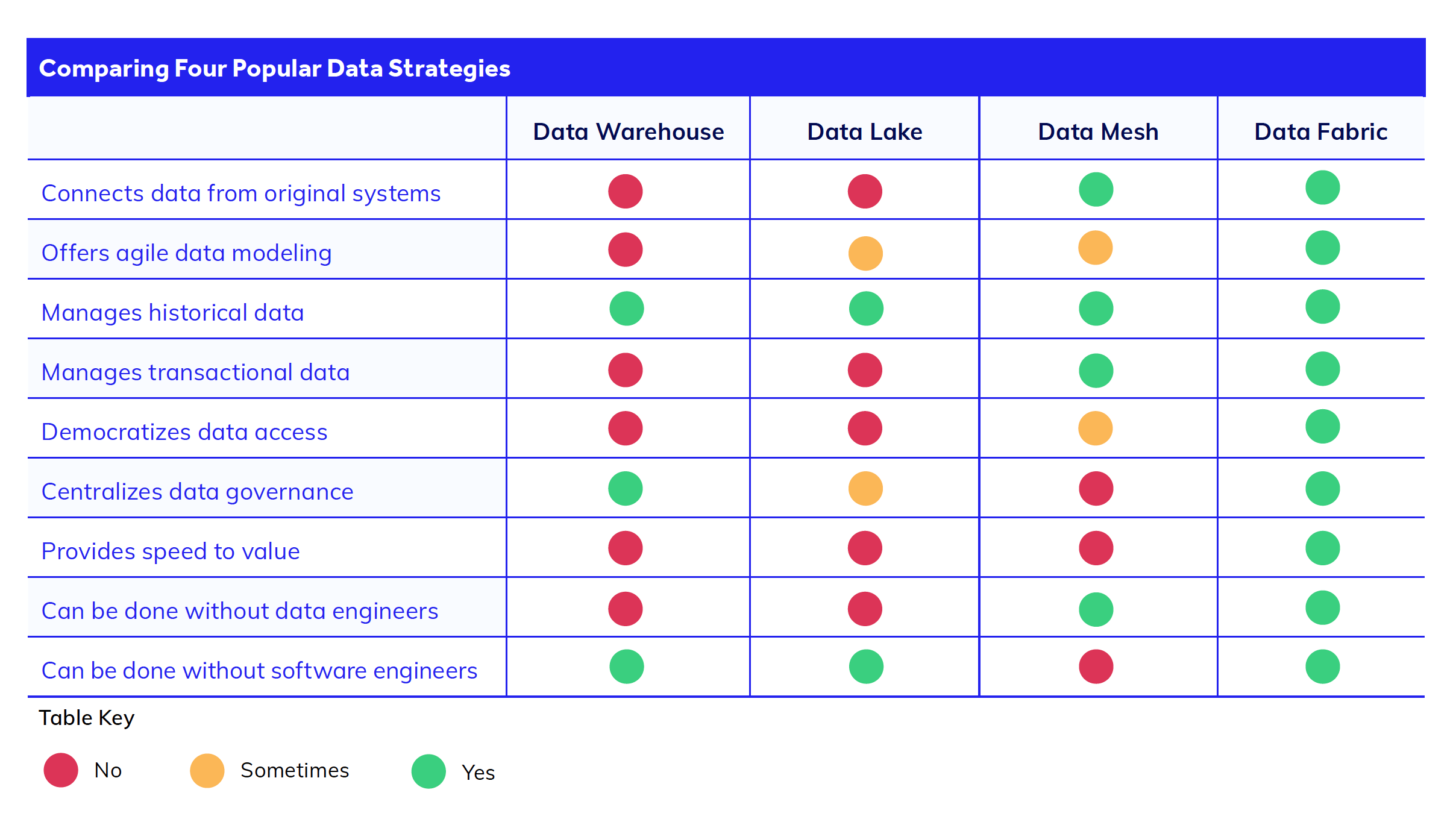
Data lake vs. data mesh vs. data fabric: qual è la differenza?
La terminologia della gestione dei dati può confondere rapidamente, quindi cerchiamo di demistificare alcuni termini che possono sembrare simili al data fabric ma che, in realtà, presentano differenze cruciali.
Data lake
Un data lake è nettamente diverso dal data fabric. Come un data warehouse, l'obiettivo principale di un data lake è solo quello di raccogliere i dati in un unico archivio, non di collegarli. I data lake sono utilizzati per grandi insiemi di dati non strutturati, mentre i data warehouse sono utilizzati per i dati strutturati.
Con un data lake, è necessario estrarre tutti i dati da ogni sistema e caricarli in un nuovo sistema (il lake). I dati rimangono nel lake fino a quando non vengono trasformati e analizzati in un secondo momento. Un data lake è adatto al lavoro analitico, ma non supporta i sistemi transazionali che richiedono dati in tempo reale, come le applicazioni CRM.
Una sfida fondamentale nell'utilizzo dei data lake per la gestione dei dati è che lo spostamento dei dati da un sistema a compartimenti stagni al lake comporta tempi e costi di sviluppo aggiuntivi. Ad esempio, gli sviluppatori non possono avviare una nuova applicazione finché i dati del lake non vengono ripuliti e migrati per essere utilizzati. Lo sviluppo, la manutenzione e la cura di questo data lake comportano nel tempo un ulteriore debito tecnico per i team di engineering.
Data mesh
Le architetture di progettazione di data fabric e data mesh, invece, adottano un approccio diverso. Entrambi si concentrano sulla connessione diretta alle fonti di dati rispetto all'estrazione di tutti i dati. Come abbiamo detto in precedenza, ciò consente di accedere ai dati in tempo reale e di evitare progetti di migrazione tempestivi e costosi.
Tuttavia, data mesh e data fabric risolvono il problema della connessione dei dati in modo diverso. Il data mesh utilizza complesse integrazioni API tra microservizi per mettere insieme i sistemi di tutta l'azienda. Quindi, con il data mesh, se da un lato si evita molto lavoro di engineering dei dati, dall'altro lo si scambia per un ulteriore sforzo di sviluppo del software che si occupa delle API.
Data fabric
Ciò che rende unico il data fabric è la sua capacità di creare un livello di dati virtualizzati in cima ai set di dati, eliminando la necessità di un complesso lavoro di API e di codifica richiesto da un data mesh o un data lake. In questo modo i team possono disporre di maggiore velocità e agilità per l'analisi dei dati, la modellazione dei dati e il lavoro di trasformazione digitale.
[ Leggi il nostro articolo correlato: Data fabric vs. data mesh vs. data lake.]
Perché utilizzare un data fabric? Perché è importante?
Un'architettura data fabric consente di collegare rapidamente i dati tra i silos aziendali. Ma molti strumenti di gestione e integrazione dei dati in circolazione affermano di poterlo fare. Perché utilizzare un data fabric, nello specifico?
Un vantaggio fondamentale dell'utilizzo di un data fabric è che copre sia i sistemi transazionali che quelli analitici.
Come già detto, i dati transazionali sono dati vivi: cambiano per supportare sistemi vivi come applicazioni di case management, software CRM e altre applicazioni in cui i dati devono essere aggiornati regolarmente per supportare le operazioni in tempo reale di un'azienda. I dati analitici sono dati storici. È una visione del passato, immutabile.
Altre architetture di gestione dei dati, come i data warehouse ed i data lake, supportano solo dati analitici. Quando i dati cambiano, o sono "mutevoli", si cominciano a vedere le crepe in queste strategie architettoniche, che possono fornire solo i dati statici estratti dai singoli sistemi. Questo comporta una latenza dei dati e influisce sull'utilità dei dati nell'applicazione. Anche queste altre architetture di dati richiedono una grande quantità di sviluppatori per estrarre, trasformare e caricare i dati in modo che possano essere utilizzati.
Al contrario, un data fabric prospera in situazioni in cui i dati cambiano continuamente, come le applicazioni che prevedono la condivisione di dati da parte dei partner. Poiché i dati sono virtualizzati e collegati direttamente ai sistemi di origine, è possibile leggere/scrivere facilmente su tali sistemi. Non è necessario alcun lavoro di migrazione. Il tuo team acquisisce dati in tempo reale per avere una visione d'insieme in tempo reale della tua organizzazione. Questa singola fonte di dati può fornire una visione completa dell'azienda, un sacro graal che molti team hanno inseguito per anni alla ricerca di risultati aziendali migliori.
Per cosa viene usato un data fabric? Esempi del mondo reale.
Che aspetto ha un data fabric nella vita reale? La tecnologia Data Fabric può essere utilizzata in un'intera organizzazione per molti casi d'uso diversi, in quanto può collegare un'ampia gamma di set di dati. Vediamo solo un paio di esempi di come un'organizzazione potrebbe utilizzare un data fabric per collegare fonti eterogenee di dati all'interno dell'azienda e migliorare la visibilità e l'efficienza.
Il data fabric nella gestione delle richieste di servizio
Molte imprese hanno un'unità aziendale che si occupa di manutenzione e servizi per i loro prodotti (macchine, utility, ecc.). Per ottimizzare l'efficienza, hanno bisogno di un'applicazione che gestisca tutti gli aspetti del processo di richiesta, quindi la business unit cerca di costruire un'applicazione per la gestione delle richieste di servizio.
Tuttavia, in genere i dati a cui devono accedere, aggiornare e su cui devono agire sono sparsi in tutta l'organizzazione. L'inventario dei ricambi risiede in un sistema ERP, le attrezzature del cliente in un database relazionale interno e le informazioni sui clienti nel loro CRM, ad esempio.
Per gestire correttamente queste richieste di assistenza, l'azienda deve collegare tutti e tre i suoi sistemi eterogenei. La migrazione in un unico bucket richiederebbe troppo tempo e sforzi, senza contare che questi dati sono in continua evoluzione e sarebbero già obsoleti una volta arrivati agli utenti aziendali.
L'organizzazione utilizza invece un'architettura data fabric per connettersi direttamente ad ogni sistema, lasciando i dati al loro posto. In questo modo si rompono i silos e si riduce al minimo il lavoro di progettazione dei dati. Il risultato sono dati in tempo reale e approfondimenti operativi in tutta l'applicazione di richiesta di assistenza, dove gli utenti possono leggere e scrivere direttamente su ogni fonte come se fossero dati locali.
Data fabric nell'onboarding dei fornitori
Molte organizzazioni devono gestire il processo di onboarding dei fornitori, siano essi membri del personale a contratto, fornitori di materiali, ecc. In questo esempio, supponiamo che un'organizzazione voglia gestire la concessione di proprietà intellettuale (IP) a terzi in base ai loro contratti con l'organizzazione.
A tal fine è necessario unire i dati degli archivi di proprietà intellettuale del marchio, le informazioni sui contratti ed i dati del CRM. È inoltre necessario tenerli aggiornati man mano che gli utenti compiono le azioni associate. In questo caso, dovrai sicuramente garantire una certa proprietà intellettuale, a seconda di quanto previsto dal contratto con il terzo.
Una piattaforma di data fabric collega tutte e tre queste fonti per consentirti di accedere alle informazioni in tempo reale e di proteggere i propri dati su più sistemi di record con una sicurezza a livello di riga. Ciò consente di fare riferimento al CRM per determinare se determinate righe di dati nel database IP devono essere visibili al contraente. Questa è la potenza della costruzione di un data fabric.
Quali sono i vantaggi aziendali dei data fabric?
Quali sono i vantaggi aziendali dell'utilizzo di un data fabric nella tua strategia di architettura di dati aziendali? I principali vantaggi del data fabric includono una maggiore velocità e agilità, la democratizzazione della modellazione dei dati, maggiori approfondimenti aziendali e una gestione centralizzata dei dati per migliorare la sicurezza e la compliance normativa.
E nessuna migrazione di dati equivale a uno sviluppo più rapido dell'applicazione. Questa è una differenza fondamentale tra i data fabric e i data warehouse o i data lake. In particolare, in tempi di sconvolgimenti della concorrenza o di recessione economica, ogni leader aziendale desidera velocità e flessibilità. È possibile ottenere un valore ancora maggiore da un'architettura data fabric combinandola con strumenti di modellazione dati no-code dotati di sicurezza a livello di record.
Senza un'architettura rigida, il data fabric consente di modificare e aggiornare facilmente i modelli di dati dell'organizzazione nel tempo. Poiché un livello di dati virtuale si trova sopra i dati, non è necessario eseguire complesse operazioni di manutenzione e si possono aggiungere, eliminare e mettere in relazione rapidamente le fonti in base alle esigenze aziendali. Inoltre, è possibile riutilizzare facilmente pezzi di lavoro tra i flussi di lavoro e le applicazioni, il che significa che gli sviluppatori possono sfruttare il lavoro esistente per evitare duplicazioni e guadagnare velocità.
Secondo Le 10 principali tendenze di Gartner in materia di dati e analisi per il 2021, Gartner ha rilevato che il data fabric riduce del 30% i tempi di progettazione dell'integrazione, del 30% quelli di implementazione e del 70% quelli di manutenzione, perché i progetti tecnologici si basano sulla capacità di utilizzare, riutilizzare e combinare diversi stili di integrazione dei dati.
La capacità di un data fabric di collegare insiemi di dati eterogenei, senza orde di specialisti di database, significa che i dati preziosi non si nascondono più nei silos. Il data fabric offre una visione completa dei dati della vostra azienda, consentendo ai vostri team di prendere decisioni migliori e basate sui dati.
L'approccio centralizzato di data fabric offre anche vantaggi sui rischi riguardanti la sicurezza e la conformità. Con un data fabric, l'IT ottiene un quadro centralizzato che mostra chi può visualizzare, aggiornare ed eliminare specifici set di dati. Poiché le organizzazioni democratizzano l'accesso ai dati, condividendone di più sia all'interno dell'organizzazione che all'esterno con clienti e partner, il data fabric dà ai team IT la certezza di disporre di un'architettura di dati amministrata e sicura. Si tratta di un aspetto importante, dato che le richieste normative continuano ad aumentare.
Per tutti questi motivi, le aziende possono sfruttare la potenza del data fabric per aumentare la velocità, migliorare le decisioni e, in ultima analisi, l'innovazione digitale.
[ Vuoi saperne di più su come un data fabric può trasformare le strategie di gestione dei dati della tua organizzazione? Guarda il nostro webinar on demand. ]
Come il data fabric si inserisce nella strategia di automazione dei processi
Come alcune aziende hanno già imparato a proprie spese, il successo dell'automazione richiede una solida architettura dei dati. Se i dati sono nascosti in silos ed i sistemi non comunicano bene, è possibile automatizzare parti di un processo, ma non l'intero processo. Questo è uno dei motivi per cui il data fabric è una funzionalità indispensabile in una piattaforma di automazione dei processi.
L'automazione dei processi si riferisce a strumenti che aiutano le imprese ad automatizzare e migliorare interi processi aziendali, come ad esempio la gestione del ciclo di vita del cliente nel settore bancario, l'ottimizzazione delle operazioni della supply chain o la velocizzazione della sottoscrizione assicurativa. Questi processi intricati e lunghi coinvolgono più persone, reparti e sistemi, che spesso includono anche la tecnologia legacy. Una piattaforma di automazione dei processi combina una serie di tecnologie per svolgere il lavoro, tra cui la Robotic Process Automation (RPA), l’intelligent document processing (IDP), l'orchestrazione dei flussi di lavoro, l’intelligenza artificiale (IA), le integrazioni di sistema e le regole di business. Tra l'altro, hyperautomation e automazione dei processi si riferiscono a questo stesso insieme di tecnologie.
Il data fabric apporta importanti funzionalità a una piattaforma di automazione dei processi, in quanto collega i set di dati tra i vari sistemi, siano essi on-premise o nel cloud. Cerca una piattaforma di automazione dei processi che fornisca anche connettori low-code o no-code, in modo da poter collegare questi sistemi (come CRM, ERP e applicazioni di database) senza creare le connessioni da zero. L'ultimo elemento indispensabile in una piattaforma è un livello di orchestrazione del flusso di lavoro, che dirige e fa passare senza problemi i flussi di lavoro tra bot software e umani.
Per le aziende che cercano velocità e agilità, una piattaforma di automazione dei processi con funzionalità di data fabric migliora anche la resilienza e la sicurezza quando si modificano i processi in risposta alle mutevoli esigenze aziendali o normative. Tieni a mente questi fattori cruciali quando aumenti i tuoi sforzi di automazione.