Data fabric: ¿qué es un tejido de datos?
A continuación, le explicamos cómo funcionan los data fabrics, por qué son importantes, la diferencia entre tejido de datos, malla de datos y lagos de datos, además de ejemplos reales y ventajas empresariales.
¿Qué es un tejido de datos y para qué sirve?
La gestión de datos en las grandes empresas nunca ha sido fácil. Sin embargo, con el auge de las tecnologías y herramientas digitales, las empresas han creado exponencialmente más datos y éstos se han fragmentado cada vez más entre las distintas aplicaciones de la organización. Con el tiempo, han surgido nuevas prácticas de gestión de datos para gestionar estos complejos problemas, como los almacenes de datos, los lagos de datos y las mallas de datos, pero para la mayoría de las empresas modernas con estructuras de datos complejas, no son suficientes.
Aunque todas ellas intentan resolver los retos que plantea la unión de datos de fuentes dispares, cada una tiene sus propias deficiencias para gestionar los datos de forma eficiente, desde el aumento o el desplazamiento de la deuda técnica hasta las largas y costosas migraciones de datos, pasando por la reducción de la integridad de los datos y los problemas de seguridad de los datos. Para superar estos retos de gestión de datos empresariales, lo que muchas organizaciones necesitan es un data fabric, lo que significa y se conoce como tejido de datos.
El data fabric también desempeña un papel clave en una plataforma moderna de automatización de procesos (o hiperautomatización) que optimice los complejos procesos empresariales de extremo a extremo. Esto es crucial cuando se busca escalar la automatización en toda la empresa y lograr una mejora holística, no solo victorias aisladas.
Definición de data fabric
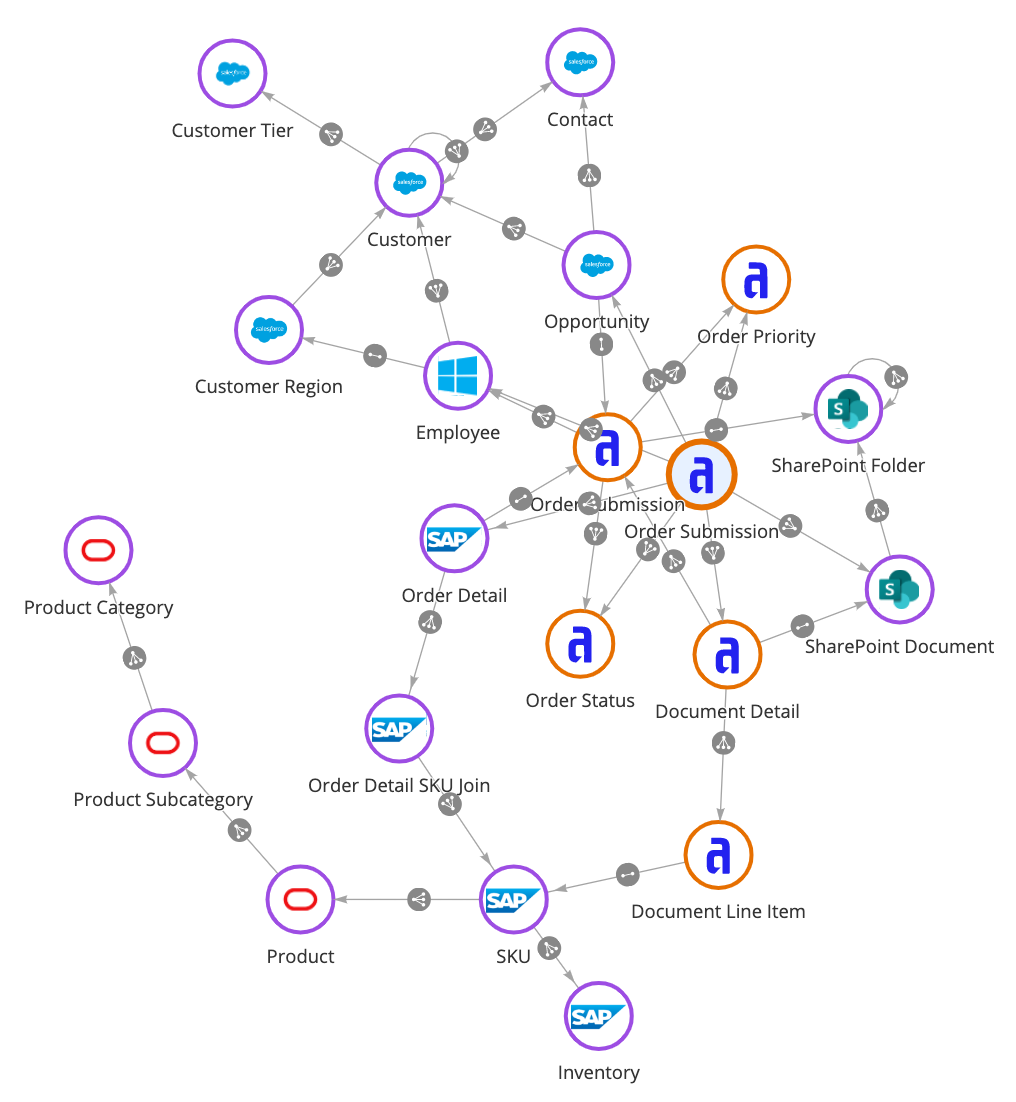
¿Qué significa data fabric? Se trata de una capa de arquitectura y un conjunto de herramientas que conectan datos de sistemas dispares y crean una visión unificada. Es una capa de datos virtualizada. Esto significa que no es necesario migrar los datos desde donde se encuentran actualmente, por ejemplo, una base de datos, un sistema de planificación de recursos empresariales (ERP) o una aplicación de gestión de relaciones con los clientes (CRM). Los datos pueden estar en las instalaciones, en un servicio en la nube o en entornos multicloud. Aplicando el enfoque del tejido de datos, puede combinar los datos empresariales de formas totalmente nuevas, con un beneficio particular para el trabajo de transformación digital. Es un concepto que Gartner llama “diseño componible”. Esa es una de las razones por las que Gartner nombró el data fabric como su principal tendencia tecnológica estratégica para 2022.
Mientras que los almacenes de datos se centran en recopilar datos, el data fabric los conecta.
El tejido de datos elimina las migraciones de datos costosas y que requieren mucho tiempo, con capacidades consistentes que conectan los datos directamente desde dondequiera que vivan, lo que le da la capacidad de poner en marcha aplicaciones y reducir drásticamente el tiempo de conocimiento para los líderes empresariales. Esto es fundamental para el trabajo de transformación digital que exige velocidad y agilidad para dar a su organización una ventaja competitiva. El data fabric también proporciona una experiencia de modelado de datos simplificada que democratiza el análisis de datos, dando acceso no solo a ingenieros y desarrolladores de datos cualificados, sino también a los empleados de la línea de negocio que necesitan información basada en datos para alcanzar sus objetivos empresariales más rápidamente.
Organizaciones de todo el mundo están utilizando un enfoque de tejido de datos para ampliar el acceso a los datos y crear una visión única, segura y completa de los datos en todas sus empresas. Esto, a su vez, impulsa la innovación digital y la toma de mejores decisiones empresariales.
[ ¿Quiere saber más sobre cómo resolver sus problemas de silos de datos y acelerar la innovación? Consiga el libro electrónico: La ventaja de un data fabric. ]
¿Cómo funciona un data fabric?
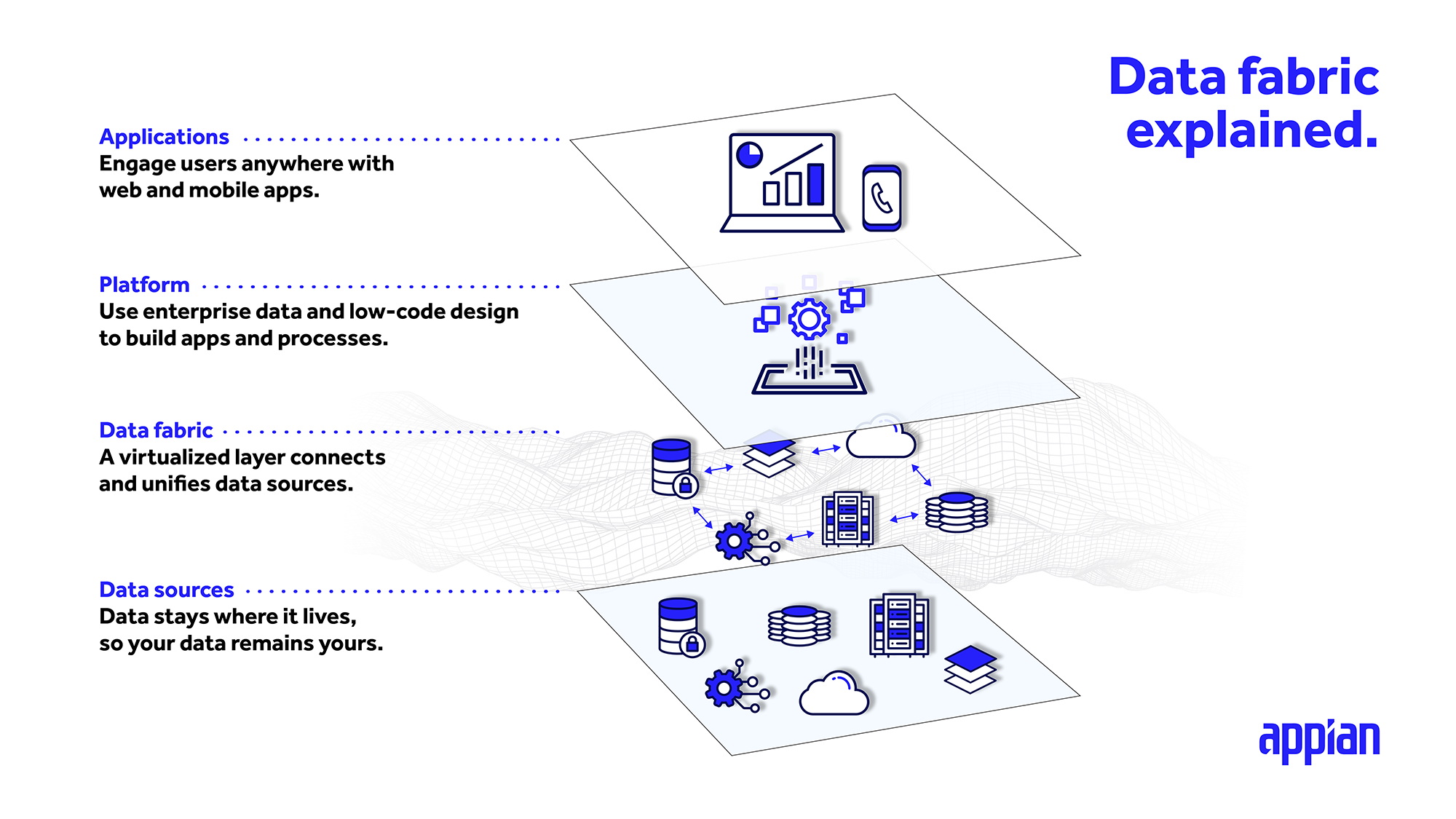
Una de las principales ventajas de un data fabric es que puede dejar los datos donde se encuentran actualmente y acceder a ellos con la misma facilidad que si estuvieran localmente en sus aplicaciones. A través de una capa integrada que se asienta sobre los sistemas y conjuntos de datos, los data fabric centralizan los datos en un solo lugar para que pueda acceder a ellos, relacionarlos y ampliarlos. También puede pensar en el data fabric como una capa de abstracción para gestionar sus datos.
Esta capa de datos integrada se conecta directamente a cada fuente, lo que le permite acceder a los datos en tiempo real y crear, leer, actualizar y eliminar (CRUD) fragmentos de datos desde cualquier lugar en el que los utilice.
Ya se trate de una aplicación CRM o ERP, o incluso de un sistema de gestión de bases de datos relacionales propio, la arquitectura de los tejidos de datos empresariales puede entrelazar fuentes dispares en un único modelo de datos unificado para su uso en múltiples aplicaciones.
[ ¿Quiere un PDF compartible de este artículo completo? Descárguelo ahora. ]
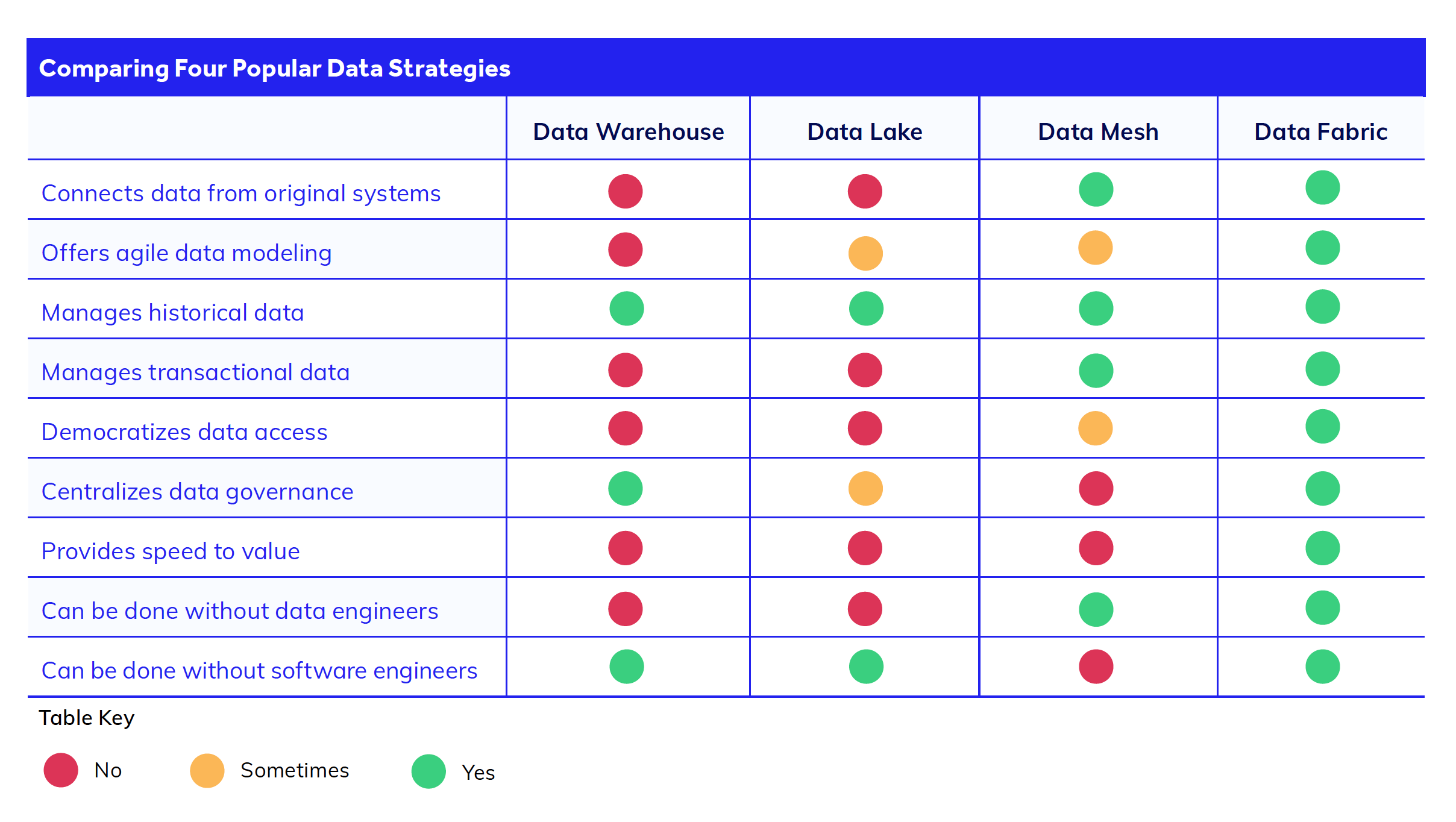
Lago de datos frente a malla de datos frente a tejido de datos: ¿cuál es la diferencia?
La terminología de gestión de datos se vuelve confusa rápidamente, así que vamos a desmitificar algunos términos que pueden parecer similares a data fabric pero que, en realidad, tienen diferencias cruciales.
Lago de datos.
Un lago de datos es claramente diferente de un data fabric. Al igual que un almacén de datos, el objetivo principal de un lago de datos es recopilar datos en un único repositorio, no conectarlos. Los lagos de datos se utilizan para grandes conjuntos de datos no estructurados, mientras que los almacenes de datos se utilizan para datos estructurados.
Con un lago de datos, hay que sacar todos los datos de cada sistema y cargarlos en un nuevo sistema (el lago). Los datos permanecen en el lago hasta que se realiza el trabajo de transformación y análisis en una fecha posterior. Un lago de datos es adecuado para el trabajo analítico, pero no es compatible con los sistemas transaccionales que requieren datos en tiempo real, como las aplicaciones CRM.
Uno de los principales problemas que plantea el uso de lagos de datos para la gestión de datos es que trasladar los datos de un sistema aislado al lago implica tiempo y costes de desarrollo adicionales. Por ejemplo, los desarrolladores no pueden poner en marcha una nueva aplicación hasta que los datos del lago se hayan limpiado y migrado para su uso. El mantenimiento del desarrollo y la conservación de este lago de datos suponen una deuda técnica adicional para los equipos de ingeniería a lo largo del tiempo.
Malla de datos
Por el contrario, las arquitecturas de diseño de data fabric y data mesh adoptan un enfoque diferente. Ambas se centran en conectarse directamente a las fuentes de datos en lugar de extraer todos sus datos. Como hemos comentado anteriormente, esto permite acceder a los datos en tiempo real y evitar proyectos de migración puntuales y costosos.
Sin embargo, la malla de datos y el tejido de datos resuelven este problema de conexión de datos de forma diferente. La malla de datos utiliza complejas integraciones de API a través de microservicios para unir los sistemas de toda la empresa. Así, con la malla de datos, si bien se evita mucho trabajo de ingeniería de datos, se cambia por esfuerzos adicionales de desarrollo de software que se ocupan de las API.
Tejido de datos (data fabric).
Lo que hace único a data fabric es su capacidad para crear una capa de datos virtualizada sobre los conjuntos de datos, eliminando la necesidad del complejo trabajo de API y codificación que requiere una malla de datos o un lago de datos. Esto proporciona a los equipos velocidad y agilidad añadidas para realizar análisis de datos, modelado de datos y trabajo de transformación digital.
[ Lea nuestro artículo relacionado: Tejido de datos frente a malla de datos frente a lago de datos].
¿Por qué utilizar un tejido de datos? ¿Por qué es importante?
Una arquitectura de data fabric le permite conectar rápidamente datos entre silos empresariales. Sin embargo, muchas herramientas integradas y de gestión de datos pretenden hacer lo mismo. Entonces, ¿por qué utilizar un tejido de datos?
Una de las principales ventajas de utilizar un data fabric es que abarca tanto los sistemas transaccionales como los analíticos.
Como ya se ha señalado, los datos transaccionales son datos vivos: cambian para dar soporte a sistemas vivos como aplicaciones de Case Management, software CRM y otras aplicaciones en las que los datos deben actualizarse regularmente para dar soporte a las operaciones en tiempo real de una empresa. Los datos analíticos son datos históricos. Es una visión del pasado, cambiante e inmutable.
Otras arquitecturas de gestión de datos, como los almacenes y los lagos de datos, solo admiten datos analíticos. Cuando los datos cambian, o son “mutables”, se empiezan a ver grietas en estas estrategias arquitectónicas, ya que solo pueden proporcionarle los datos estáticos que se extrajeron de los sistemas individuales. Esto conduce a la latencia de los datos y afecta a la utilidad de los datos en su aplicación. Además, estas otras arquitecturas de datos siguen requiriendo una gran cantidad de desarrolladores para extraer, transformar y cargar los datos para que puedan utilizarse.
Por el contrario, un d data fabric prospera en situaciones en las que los datos cambian constantemente, como las aplicaciones que implican el intercambio de datos entre socios. Como los datos están virtualizados y conectados directamente a los sistemas de origen, se puede leer y escribir fácilmente en esos sistemas. No se requiere ningún trabajo de migración. Su equipo obtiene datos en tiempo real para obtener información en tiempo real sobre su organización. Esta única fuente de datos puede ofrecerle una visión completa de su negocio, un santo grial que muchos equipos han perseguido durante años en busca de mejores resultados empresariales.
¿Para qué se usa el data fabric? Ejemplos reales.
¿Qué aspecto tiene un tejido de datos en la vida real? La tecnología de data fabric puede utilizarse en toda una organización para muchos casos de uso diferentes, ya que puede conectar una amplia gama de conjuntos de datos. Veamos solo un par de ejemplos de cómo una organización podría utilizar un data fabric para conectar fuentes de datos dispares en toda la empresa con el fin de mejorar la visibilidad y la eficiencia.
El tejido de datos en la gestión de solicitudes de servicio.
Muchas empresas tienen una unidad de negocio que se ocupa del mantenimiento y los servicios de sus productos (máquinas, servicios públicos, etc.). Con el fin de racionalizar la eficiencia, necesitan una aplicación para gestionar todos los aspectos del proceso de solicitud, por lo que la unidad de negocio busca crear una aplicación de gestión de solicitudes de servicio.
Pero normalmente los datos a los que necesitan acceder, actualizar y accionar están repartidos por toda la organización. Por ejemplo, el inventario de piezas se encuentra en un sistema ERP, el equipo del cliente en una base de datos relacional propia y la información del cliente en su CRM.
Para gestionar correctamente estas solicitudes de servicio, la empresa necesita conectar sus tres sistemas dispares. Migrarlos a un único bucket llevaría demasiado tiempo y esfuerzo, por no mencionar que estos datos son cambiantes y estarían obsoletos para cuando llegaran a los usuarios de la empresa.
En su lugar, la organización utiliza una arquitectura de data fabric para conectarse directamente a cada sistema, dejando los datos en su lugar actual. Esto rompe los silos y minimiza el trabajo de diseño de datos necesario. El resultado son datos en tiempo real y perspectivas operativas en toda la aplicación de solicitud de servicios, donde los usuarios pueden leer y escribir directamente en cada fuente como si fueran datos locales.
El tejido de datos en la incorporación de proveedores.
Muchas organizaciones tienen que gestionar el proceso de incorporación de proveedores, ya sean trabajadores contratados, proveedores de materiales, etc. En este ejemplo, supongamos que una organización desea gestionar la concesión de propiedad intelectual (PI) a terceros en función de sus contratos con la organización.
Para ello será necesario fusionar los datos de los almacenes de propiedad intelectual de la marca, la información de los contratos y los datos de CRM. También necesitaría mantenerla actualizada a medida que los usuarios realicen sus acciones asociadas. Y en este caso, definitivamente necesitarías asegurar cierta propiedad intelectual, dependiendo de lo que el contrato del tercero les proporcione.
Una plataforma de data fabric conecta estas tres fuentes para permitirle acceder a información en tiempo real y proteger sus datos en varios sistemas de registro con seguridad a nivel de fila. Esto le permite hacer referencia a su CRM para determinar si ciertas filas de datos en su base de datos IP deben ser visibles para el contratista. Es el poder de construir un data fabric.
¿Cuáles son las ventajas empresariales de los tejidos de datos?
¿Cuáles son las ventajas empresariales de utilizar un tejido de datos en su estrategia de arquitectura de datos empresariales? Entre las principales ventajas del data fabric se incluyen la mejora de la velocidad y la agilidad, la democratización del modelado de datos, una visión empresarial más procesable y la gestión centralizada de datos para mejorar la seguridad y el cumplimiento.
Y la no migración de datos equivale a un desarrollo de aplicaciones más rápido. Esta es una diferencia clave entre el data fabric y los almacenes o lagos de datos. Especialmente en tiempos de disrupción competitiva o recesión económica, todos los líderes empresariales quieren velocidad y flexibilidad. Puede obtener aún más valor de una arquitectura de data fabric combinándola con herramientas de modelado de datos sin código que tengan seguridad a nivel de registro.
Sin una arquitectura rígida, el tejido de datos le permite cambiar y actualizar fácilmente los modelos de datos de su organización a lo largo del tiempo. Dado que una capa de datos virtual se asienta sobre los datos, no es necesario realizar tareas de mantenimiento complejas y se pueden añadir, eliminar y relacionar fuentes rápidamente a medida que cambian las necesidades de la empresa. Además, puede reutilizar fácilmente partes del trabajo en workflows y aplicaciones, lo que significa que los desarrolladores pueden aprovechar el trabajo existente para evitar la duplicación de esfuerzos y ganar velocidad.
Según el informe de Gartner Top 10 Data and Analytics Trends for 2021, Gartner descubrió que el data fabric reduce el tiempo de diseño de la integración en un 30 %, el despliegue en un 30 % y el mantenimiento en un 70 % porque los diseños de la tecnología se basan en la capacidad de utilizar, reutilizar y combinar diferentes estilos de integración de datos.
El poder de un tejido de datos para conectar conjuntos de datos dispares —sin hordas de especialistas en bases de datos— significa que los datos valiosos ya no se esconden en silos. El data fabric le ofrece una visión completa de los datos de su empresa, lo que permite a sus equipos tomar mejores decisiones basadas en datos.
El enfoque centralizado del data fabric también ofrece ventajas en cuanto a riesgos de seguridad y cumplimiento de normativas. Con un tejido de datos, el departamento de TI obtiene una imagen centralizada que muestra quién puede ver, actualizar y eliminar conjuntos de datos específicos. A medida que las organizaciones democratizan el acceso a los datos, compartiendo más datos tanto dentro de la organización como fuera de ella con clientes y partners, el data fabric ofrece a los equipos de TI la confianza de disponer de una arquitectura de datos gobernada y segura. Esto es importante a medida que aumentan las exigencias normativas.
Por todas estas razones, las empresas pueden aprovechar el poder de un tejido de datos para impulsar una nueva velocidad, mejores decisiones y, en última instancia, la innovación digital.
[ ¿Quiere saber más sobre cómo un data fabric puede transformar las estrategias de gestión de datos de su organización? Ver el webinar a la carta. ]
Cómo encaja el data fabric en la estrategia de automatización de procesos.
Como algunas empresas ya han aprendido por las malas, el éxito de la automatización requiere una arquitectura de datos sólida. Si los datos se ocultan en silos y los sistemas no se comunican bien, es posible que se puedan automatizar partes de un proceso, pero no todo el proceso de principio a fin. Este es uno de los motivos por los que el data fabric es una función imprescindible en una plataforma de automatización de procesos.
La automatización de procesos hace referencia a herramientas que ayudan a las empresas a automatizar y mejorar procesos empresariales completos, como la gestión del ciclo de vida del cliente en banca, la optimización de las operaciones de la cadena de suministro o la aceleración de la suscripción de seguros. Estos intrincados y largos procesos implican a múltiples personas, departamentos y sistemas, que a menudo incluyen tecnología heredada. Una plataforma de automatización de procesos combina una serie de tecnologías para realizar el trabajo, como la automatización robótica de procesos (RPA), el procesamiento inteligente de documentos (IDP), la orquestación de workflows, la inteligencia artificial (IA), las integraciones de sistemas y las reglas de negocio. Por cierto, la hiperautomatización y la automatización de procesos hacen referencia a este mismo conjunto de tecnologías.
El data fabric aporta capacidades importantes a una plataforma de automatización de procesos, ya que conecta conjuntos de datos entre varios sistemas, ya estén en las instalaciones o en la nube. Busque una plataforma de automatización de procesos que también proporcione conectores de bajo o ningún código para que pueda vincular esos sistemas (como CRM, ERP y aplicaciones de bases de datos) sin crear las conexiones desde cero. La última pieza imprescindible en una plataforma es una capa de orquestación del workflow, que dirige y transmite sin problemas los workflows entre los robots de software y los humanos.
Para las empresas que buscan velocidad y agilidad, una plataforma de automatización de procesos con capacidades de data fabric también mejora la resistencia y la seguridad a medida que se ajustan los procesos en respuesta a las cambiantes demandas empresariales o normativas. Tenga en cuenta estos factores cruciales a medida que amplía sus esfuerzos de automatización.