データファブリックとは?
データファブリックとは?
データファブリックとは 異なるシステム間のデータをつなぎ、一元的な視点を提供するためのアーキテクチャ層でありツールセットです。
仮想化されたデータ層として、データレイク、データウェアハウス、リレーショナルデータベース、SAPのようなERPシステム、SalesforceのようなCRM、またはSaaSアプリケーションといったデータが保存されている場所から、データを移行することなくデータにアクセスできます。データはオンプレミス、クラウドサービス、またはマルチクラウド環境に存在する場合があります。
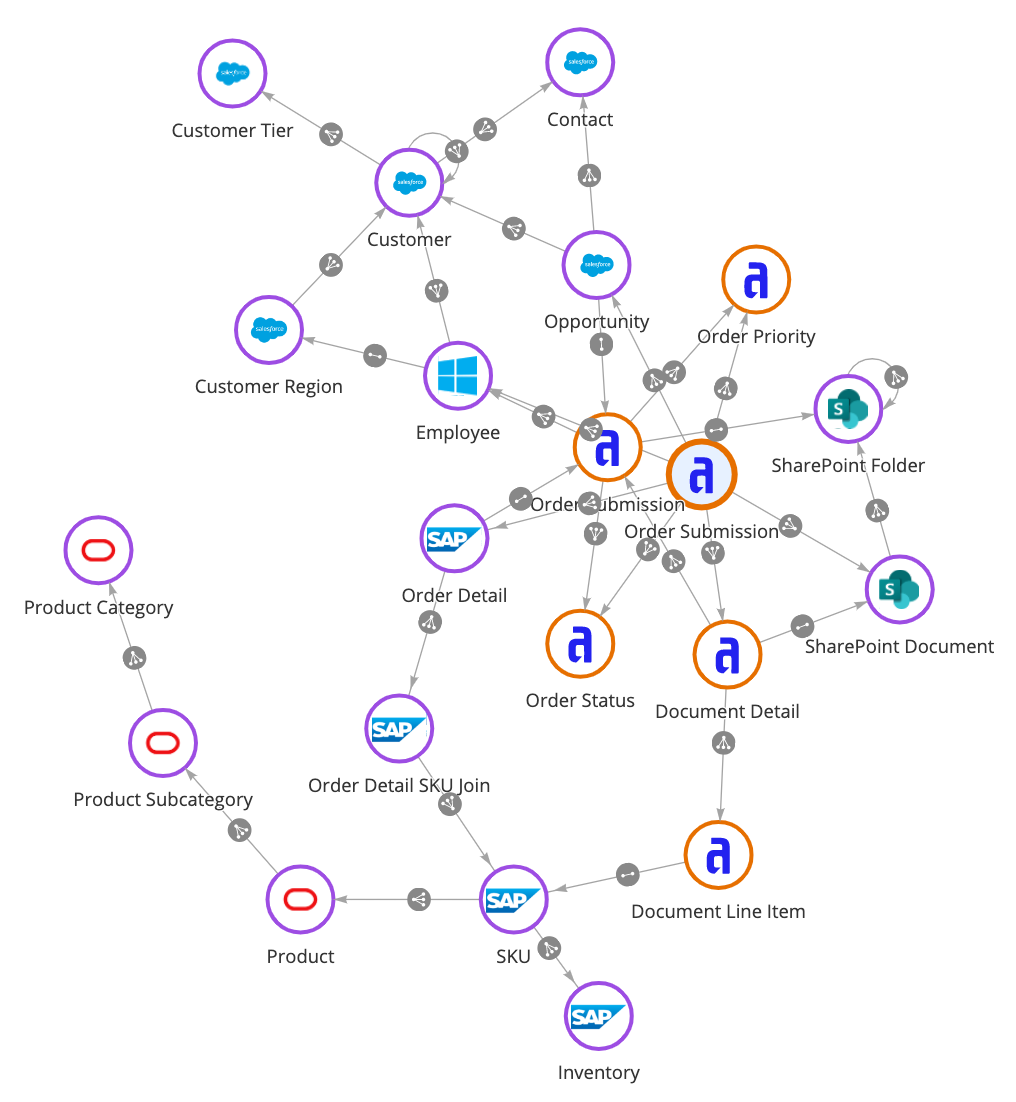
システムや場所を越えて企業データを統合するデータファブリック
データファブリックは何のために使われるのか?
デジタル技術やツールの普及により、企業のデータ量は飛躍的に増加しました。その結果、その結果、組織内の様々なアプリケーションにデータが分散し、断片化しています。
これまでに、データウェアハウス、データレイク、データレイクハウス、データメッシュなど、これらの複雑なデータ問題を管理するための新しい手法が生まれました。しかし、複雑なデータ構造を持つ多くの現代の企業にとって、これらの方法は効率的なデータ管理においてそれぞれ短所を持っています。技術的負債の増加や移行、長期にわたる高コストのデータ移行、データの完整性とセキュリティの課題が存在します。
多くの企業がこのような企業データ管理の課題を解決するために必要なのがデータファブリックです。
データファブリックは、ビジネスプロセスを全体的に最適化する現代のプロセス自動化プラットフォームにおいて重要な役割を果たします。これは、単発的な成果ではなく、企業全体にわたる自動化の拡大を通じて全面的な改善を目指す際に欠かせない要素となります。

データ管理アプローチ
上述のように、企業全体でデータを管理するためには複数の戦略があります。ここでは、ここでは、それらの手法を見ていくことで、なぜこれらが現代の迅速に進化する企業の要求に応えられないのかを理解しましょう。
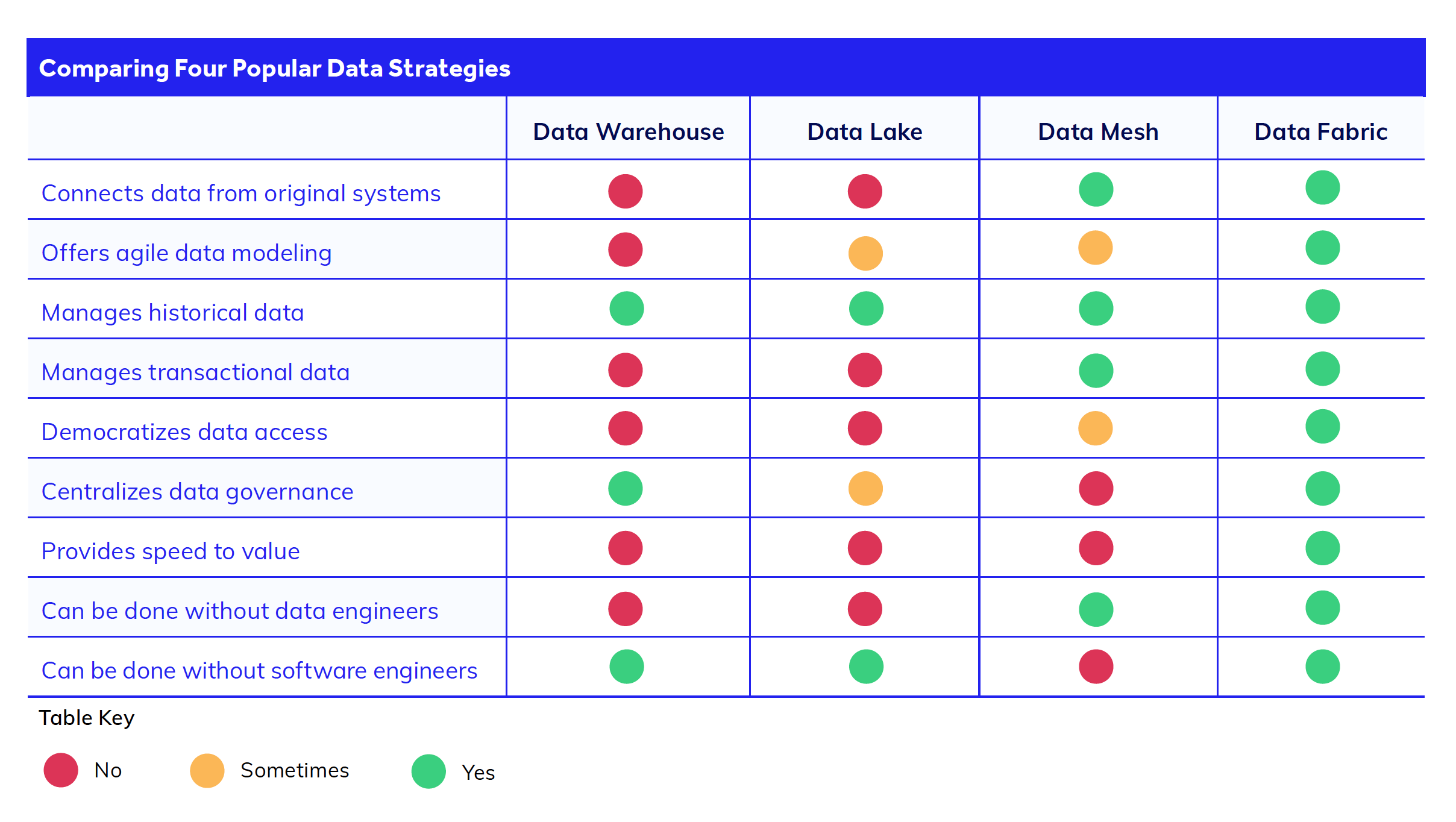
データウェアハウス、データレイク、データレイクハウス
これらのアプローチの主な目的は、データを接続するのではなく、単一のリポジトリに集約することです。
データウェアハウスは、分析のために構造化された運用データを保存します。
データレイクは、後でクリーニングや分析を行うための大量の非構造化データを保存します。
データレイクハウスは、データレイクのデータの種類に対する柔軟性と、データウェアハウスの高品質なデータコンポーネントを組み合わせます。
データウェアハウス、データレイク、データレイクハウスは、分析や運用レポートに優れたツールですが、それでも孤立したシステムからすべてのデータを抜き出して新しいシステム(ウェアハウス、レイク、またはレイクハウス)にロードする必要があります。これは、さらに別の孤立したシステムのメンテナンスと技術的な負債を意味します。さらに、データを利用可能にするためには、開発者がデータを抽出、変換、ロードする作業が必要で、開発時間とコストが追加されます。
データウェアハウスがデータの収集に焦点を当てている一方で データファブリックはデータをつなぐ
さらに、これらのリポジトリは過去のデータを用いた分析作業には適していますが、CRMアプリケーションのようにリアルタイムデータが必要なトランザクションシステムには対応していません。
データメッシュ
対照的に、データファブリックとデータメッシュのアーキテクチャ設計は異なるアプローチを取ります。これらは、すべてのデータを抽出するのではなく、直接データソースに接続することに重点を置いています。これにより、リアルタイムデータにアクセスでき、時間とコストがかかる移行プロジェクトを回避することができます。
しかし、データメッシュとデータファブリックは、このデータ接続の問題を異なる方法で解決します。データメッシュは、企業全体のシステムを繋ぐためにマイクロサービス間で複雑なAPI統合を使用します。データメッシュを採用することで、多くのデータエンジニアリング作業を回避できますが、その代わりにAPIの取り扱いに関する追加のソフトウェア開発労力が必要になります。
データファブリック
データファブリックがユニークなのは、データセットの上に仮想化層を作成する能力にあります。これにより、データメッシュ、データウェアハウス、データレイク、データレイクハウスで必要とされる複雑なAPIやコーディング作業が不要になります。このため、チームはデータ分析、データモデリング、デジタルトランスフォーメーション作業をより迅速かつ柔軟に進めることができます。

データファブリックの仕組み
データファブリックの主な利点の一つは、データを現在の場所にそのまま残しておきながら、あたかもローカルのアプリケーション内にあるかのように簡単にアクセスできることです。システムやデータセットの上に位置する統合層を通じて、データファブリックはデータを一箇所に集約し、アクセス、関連付け、拡張を容易にします。また、データファブリックはデータを管理するための抽象化層と考えることもできます。
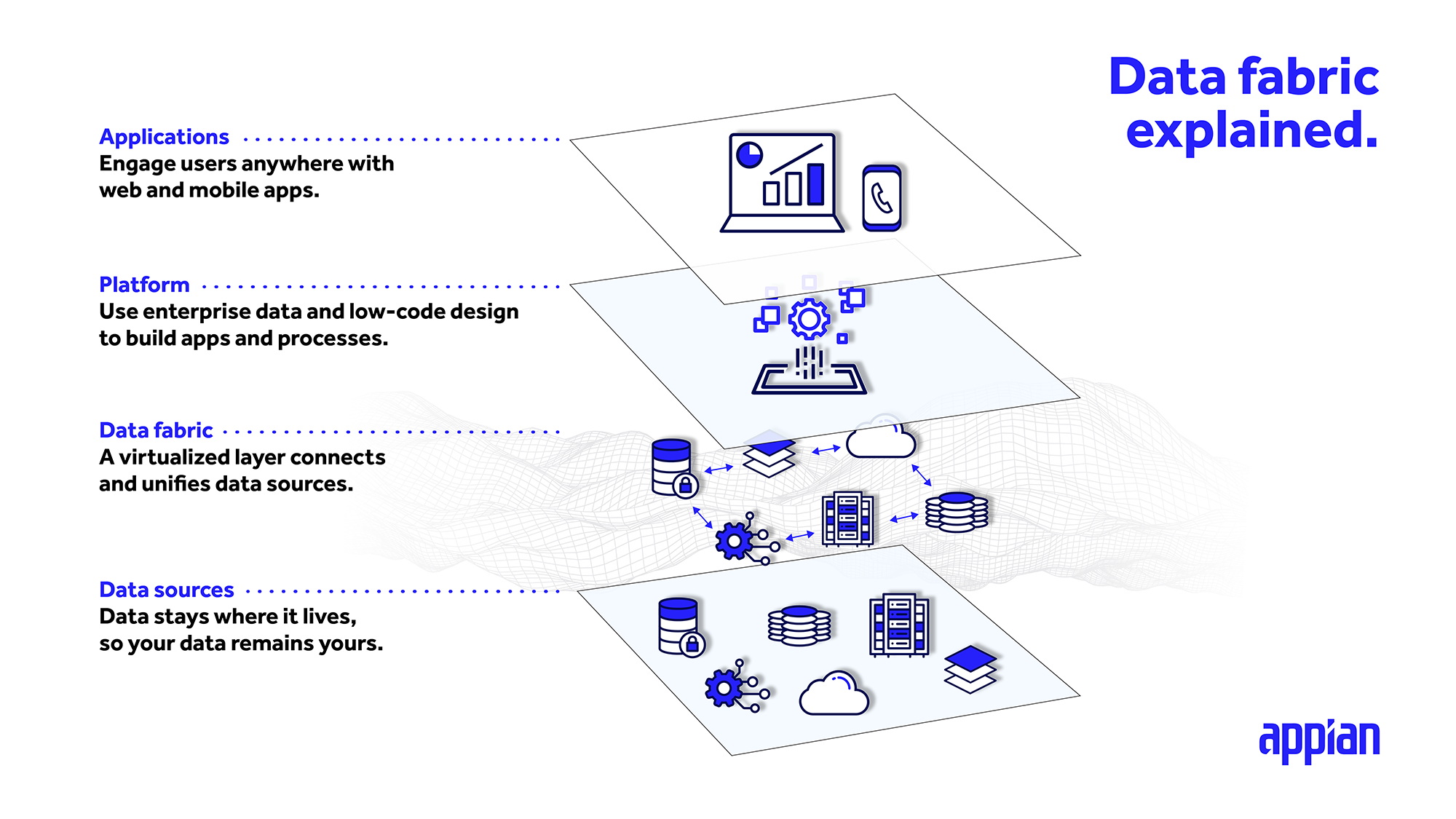
この統合データ層は、各ソースに直接接続し、リアルタイムでデータにアクセスし、どこからでもデータの作成、読み取り、更新、削除(CRUD)を行うことができます。
CRMやERPアプリケーション、あるいは独自開発のリレーショナルデータベース管理システムであっても、エンタープライズ・データファブリック・アーキテクチャは、異なるデータソースを一つの統一されたデータモデルに織り交ぜ、複数のアプリケーションで利用できるようにします。
データファブリックとメリットのその重要性
データファブリックアーキテクチャは、企業内のサイロ化されたデータを迅速につなぐことができます。しかし、市場には同様の機能を持つデータ管理や統合ツールが数多くあります。では、なぜ特にデータファブリックを選ぶ必要があるのでしょうか?
データファブリックを使用する主なメリットの一つは、トランザクションシステムと分析システムの両方をカバーできること
データファブリックは、データが頻繁に変更されるような状況や環境、例えば異なるビジネスパートナー間でデータを共有するアプリケーションでその力を発揮します。データファブリックはデータを仮想化して直接ソースシステムに接続するため、システムからのデータの読み取りや書き込みが容易に行えます。れにより、データの移動や再配置の必要がありません。そして、この一元化されたデータソースからは、ビジネスの全体像を捉えることができるため、組織全体の効果的な意思決定や戦略立案が可能となります。この一元的なデータソースは、ビジネスの完全なビューを提供します。これは、多くの企業が長年にわたって追求してきた「理想の状態」、つまりより良いビジネス成果を達成するための重要な手段なのです。
データファブリックのメリット
データファブリックを活用する主なメリットは次のとおりです。
データのサイロ化を解消:異なるデータセットをつなぎ合わせることで、データが分断された状態(サイロ化)を解消します。これにより、異なるデータベースやシステム間でのデータの統合が容易になります。
意思決定の改善:組織内の全データを一元的に把握できるため、より情報に基づいた正確な意思決定が可能になります。これは、経営層からフロントラインの従業員まで、全てのレベルでの判断を支援します。
開発時間とコストの削減データをその保管場所から直接利用できるため、データを別のシステムへ移行する際にかかる時間やコストを削減できます。これにより、ITプロジェクトの効率が向上します。
アジリティの向上:データの仮想層を通じて、組織が迅速にデータモデルを調整・更新できるようになります。これは、ビジネスの変化に素早く対応する能力を高め、柔軟性を提供します。仮想データレイヤーがデータの上に位置しているため、複雑な保守作業が不要で、ビジネスニーズに応じてソースを迅速に追加、削除、関連付けることができます。
データモデリング体験の簡素化:データモデリングを容易にし、データ分析を広範囲の従業員に解放します。これにより、専門的なスキルを持たないビジネスユーザーでもデータを活用して迅速に業務の意思決定を行うことができます。
セキュリティとコンプライアンスリスクの軽減:データの利用、管理、セキュリティに関する権限を集中的に管理することで、不正アクセスやデータ漏洩のリスクを減少させ、規制へのコンプライアンスを強化します。
Gartner®の『Top 10 Data and Analytics Trends for 2021(2021年のデータと分析に関するトップ10のトレンド』によると、データファブリックがデータ統合設計の時間を30%、データの展開時間を30%、そして保守の時間を70%削減したと報告しています。
これらの理由から、企業はデータファブリックを活用することで競争優位性を得ることができると言えます。つまり、データファブリックは、ビジネスがデータをより効率的に管理し、そのデータから最大限の価値を引き出す手段として機能するというわけです。

データファブリック実例
実際にデータファブリックはどのように活用されるのでしょうか? データファブリック技術は、幅広いデータセットを接続できるため、さまざまな用途にわたって組織全体で利用することができます。ここでは、企業がデータファブリックを活用して企業全体の異なるデータソースを接続し、可視性と効率を向上させる方法のいくつかの例を見てみましょう。
サービスリクエスト管理におけるデータファブリック
多くの企業では、製品(機器や設備など)の保守やサービスを扱う専門部門が存在します。プロセス全体を効率的に管理するために、この部門はサービスリクエスト管理アプリケーションを開発することが求められます。
しかし、必要とされるデータは組織全体に分散しているのが通常です。例えば、部品の在庫情報はERPシステムに、顧客の機器情報は独自のリレーショナルデータベースに、顧客情報はCRMシステムに格納されています。
これらのサービスリクエストを適切に処理するためには、これら3つの異なるシステムを連携させる必要があります れらを一つのシステムに統合することは、時間と労力がかかりすぎます。その上、データは常に更新されているため、ビジネスユーザーに届く頃には古くなってしまいます。
そこで、組織はデータファブリックアーキテクチャを利用して、各システムに直接接続しつつデータを現在の場所に留める方法を採用しています。これにより、サイロ化を解消し、必要なデータ設計の作業を最小限に抑えることができます。結果として、サービスリクエストアプリケーションを通じてリアルタイムのデータと運用洞察を得ることができ、ユーザーはまるでローカルデータであるかのように各データソースに直接読み書きすることが可能です。
ベンダーオンボーディングにおけるデータファブリック
多くの組織は、契約労働者や材料の供給業者など、ベンダーのオンボーディングプロセスを管理する必要があります。この例では、組織が契約に基づいて第三者に知的財産(IP)の権利を付与する管理を行いたいとします。
これを実現するには、ブランドの知的財産データ、契約情報、CRMデータを一元化する必要があります。また、ユーザーがそれぞれのアクションを取るごとにこれらの情報を最新の状態に更新することも必要です。この場合、第三者の契約内容に応じて特定の知的財産をしっかり保護することが絶対に必要になります。
データファブリックプラットフォームは、これら3つの情報ソースを接続し、リアルタイムで情報にアクセスし、行レベルのセキュリティで複数の記録システムを通じてデータを保護することを可能にします。これにより、CRMを参照して、IPデータベース内の特定のデータ行が契約業者に表示されるべきかどうかを判断することができます。これがデータファブリック構築の力です。
プロセスオートメーション戦略におけるデータファブリックの役割
自動化を成功させるには、強固なデータアーキテクチャが不可欠です。システム間の連携がうまく行かず、データが分散している場合、プロセスの一部を自動化することはできても、プロセス全体を端から端まで完全に自動化することはできません。これが、プロセス自動化プラットフォームにおいてデータファブリックが必要とされる理由の一つです。
プロセスオートメーションとは、企業がビジネスプロセス全体を自動化し、改善するためのツールのことを言います。例えば、銀行業における顧客ライフサイクルの管理、サプライチェーン運用の最適化、保険引受のスピードアップなどがあります。これらのプロセスは多くの場合、多数の人員、部門、システムを必要とし、しばしばレガシー技術も関わっています。プロセスオートメーションのプラットフォームは、ロボティック・プロセス・オートメーション(RPA)、インテリジェント・ドキュメント・プロセス(IDP)、ワークフローオーケストレーション、人工知能(AI)、システム統合、ビジネスルールなど、多様な技術を組み合わせて業務を遂行します。
データファブリックは、オンプレミスでもクラウドでも、様々なシステム間のデータセットを接続する重要な機能をプロセス・オートメーション・プラットフォームに提供します。システム(CRM、ERP、データベースアプリケーションなど)を一から構築することなく接続できるローコードまたはノーコードコネクタを備えたプロセス自動化プラットフォームを選ぶことが推奨されます。さらに、プラットフォームで必須のもう一つの要素は、ソフトウェアボットと人間の間でワークフローを指示しスムーズに受け渡すワークフロー・オーケストレーション・レイヤーです。
ビジネスや規制の変化に応じてプロセスを調整する際に、耐久性とセキュリティも向上させるデータファブリック機能を持つプロセス自動化プラットフォームを採用することは、速度と機敏性を求める企業にとって有効です。自動化を拡大する際には、これらの重要な要素を考慮に入れることが重要です。

Appianは、ビジネスプロセスのオーケストレーションを実現するソフトウェアを提供しています。Appian Platformは、重要なプロセスの設計から自動化、そして最適化まで、業務効率化を担うビジネスリーダーを一貫してご支援いたします。業界をリードするプラットフォームとカスタマーサクセスへのコミットメントにより、Appianは世界のトップ企業のお客様から信頼され、ビジネスプロセスの変革を推進しています。
©2024 Appian. All rights reserved.