Budget cuts. This dreaded term has become all too familiar in the modern economic climate. Whether cutting software spend, head count, and professional services, or optimizing supply chain, productivity, and organizational overhead, companies across the globe are trying to reduce inefficiency and waste.

The savvy leader will agree that objective, data-driven decisions are the most likely to achieve desired business impact. Unfortunately, traditional methods for process analysis are lengthy, expensive, and often subjective (if not outright inaccurate), making that ideal difficult. So how can we accurately and sustainably identify and address process inefficiencies that will lead to the greatest ROI?
One answer is bottleneck analysis. Today, we’ll explore what bottleneck analysis is, common causes for bottlenecks, and how you can use a tool called process mining to replace subjective analysis with data-driven insights to perform and take action on your own bottleneck analysis.
What is bottleneck analysis?
The shape of the neck of the glass bottle of your favorite beverage controls the flow of the goods, and business processes are no different. Process bottleneck analysis quantifies and identifies inefficiencies that result from the shape and flow of your process.
You might be familiar with some common examples of bottleneck analysis:
- How can a manufacturing plant optimize production of an exact amount of goods?
- How can a shipping company manage its warehouse supplies and fleet of trucks?
- How can a restaurant maximize the number of customers served?
These examples are only the tip of the iceberg—industries where the data is typically easy to observe and access for analysis. But in heavily-regulated industries or industries with complex IT systems, data is often opaque, if accessible in the first place. That’s precisely why these industries stand to reap the greatest benefit from being able to analyze and optimize their processes. For example:
- How can a public agency more efficiently document and execute purchases in order to respond to new mandates?
- How can a wealth management firm onboard customers more quickly in order to improve customer experience?
- How can a hospital minimize wait time to treat patients in order to maximize impact?
The key to answering these questions and realizing results lies in identifying not only the bottlenecks in the process, but also the root causes that must be addressed.
What causes process bottlenecks? 5 potential causes.
When starting an analysis of a process, there are a few symptoms of bottlenecks you’re likely to see:
- Long times to complete a step in the process.
- Long wait times between steps of the process.
- Commonly reworked steps in the process.
- Highly varied process completion times.
While “throwing more people at the problem” might alleviate these bottleneck symptoms, it often only delays true resolution. To drive lasting process improvements, you’ll need to address the root causes of these process inefficiencies. Here are five common root causes that you’ll encounter:
1. Lack of access.
Access policies typically aren’t analyzed as part of process analysis, but access issues can certainly create bottlenecks. Whether a contributor is waiting for approval to access key data, or a reviewer is unable to find or access supporting data, lack of access is one of the most common causes of delays and frustration.
2. Lack of standardization.
Often, strong individual contributors develop innovative ways to execute processes that are adopted throughout the organization. Over time, this can make processes messy and untrackable—making changes to those processes more difficult and less effective.
3. Lack of specialization.
On the other hand, new requirements or specialized problems can create processes that are too restrictive for smaller groups. For example, if a group that typically creates highly regulated content with a thorough review process begins to develop content for other departments or functions, they might run into delays because they still have to run the non-regulated content through the onerous review process. Instead, the new lines of content should have their own specialized process to maximize efficiency.
4. Lack of automation.
Manual processes are time-consuming and prone to human error. The more complex and rote a task is, the higher the risk of human variance in quality, and the higher the potential ROI of automating the task. For example, if an employee has to extract information from documents by hand, using automation tools like intelligent document processing (IDP) can significantly improve process efficiency as well as employee job satisfaction.
5. Improper automation.
Automation applied improperly, however, can also be the source of inefficiencies. Technologies such as robotic process automation (RPA) are most effective in very specific conditions. For example, RPA works best with UIs that don't change often, and using bots outside of those conditions often leads to high error rates that require more time and resources to address.
When it’s time to analyze your processes for inefficiencies, you need an objective way to map them and discover the root causes. This is where process mining comes in.
Process mining for bottleneck analysis.
Without going too deep into how process mining works, process mining is a process analytics toolset that enables continuous process improvement. It provides transparency into business processes, delivers insights, and gives you a way to take action.
[ Get a full explanation of process mining: Process Mining Guide ]
Process mining extends traditional methods for bottleneck analysis like Six Sigma’s DMAIC or Value-Stream Mapping, which provide the conceptual foundation for process improvement but don’t provide a tool to gather or visualize the data you need to analyze. When data in complex systems is hard to find or access, leaders might find themselves resorting to standing over employees’ shoulders with a stopwatch. Because of the limited tools available, such manual analysis tends to be time-consuming and subjective—even if you take as many measures as possible to be objective.
Process mining interprets process data, then presents it in a visual format that makes it easy to identify areas that need to be optimized. To do this, it interprets event logs from software that the process interacts with, and provides a way to analyze the root cause of any process issue, such as a bottleneck, that it identifies. Because process mining is based on time-stamped data, it provides an objective way to analyze a process. Instead of making guesses about where bottlenecks lie and their impact, you have data to show where bottlenecks occur, how often, and for how long.
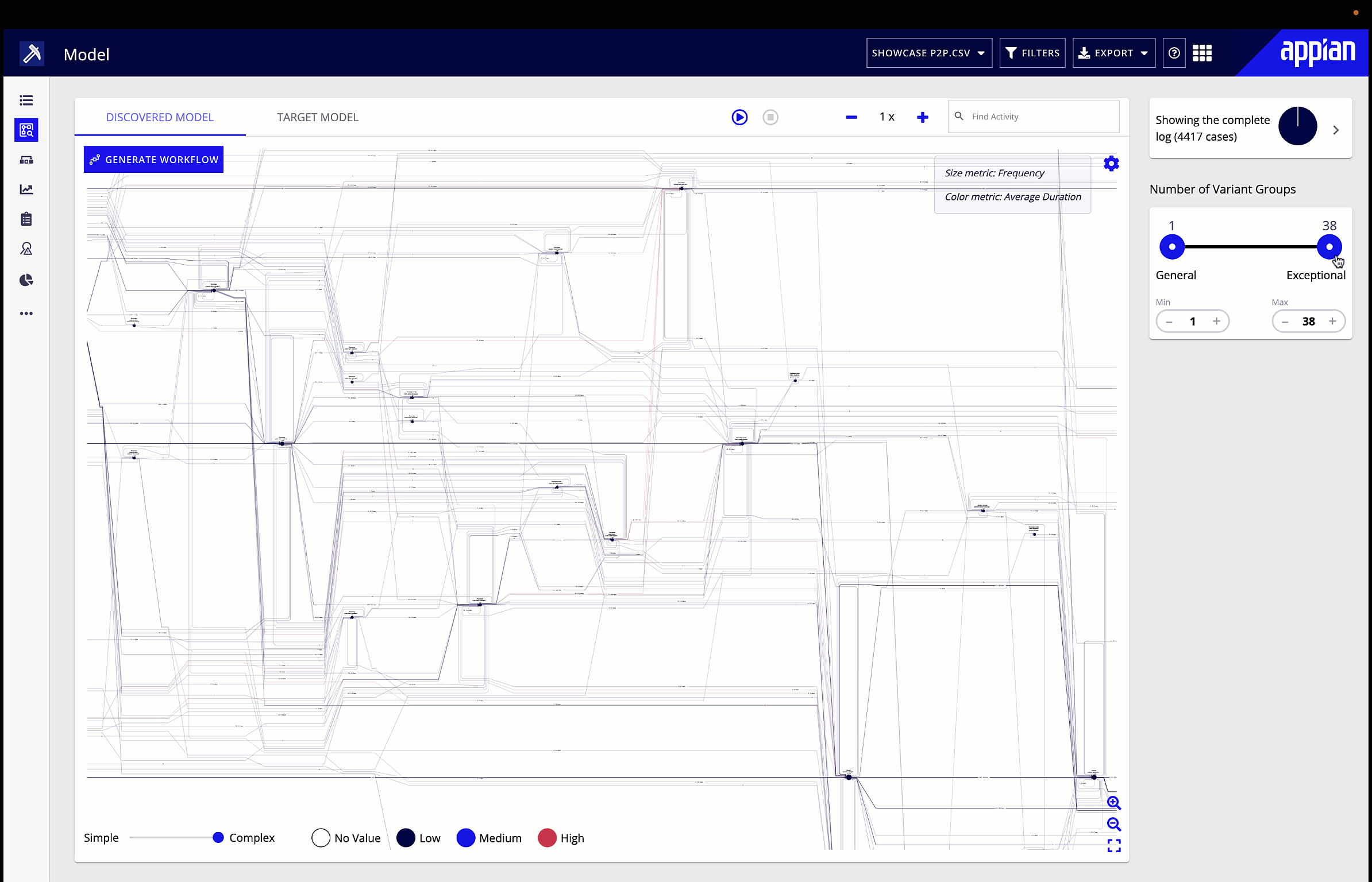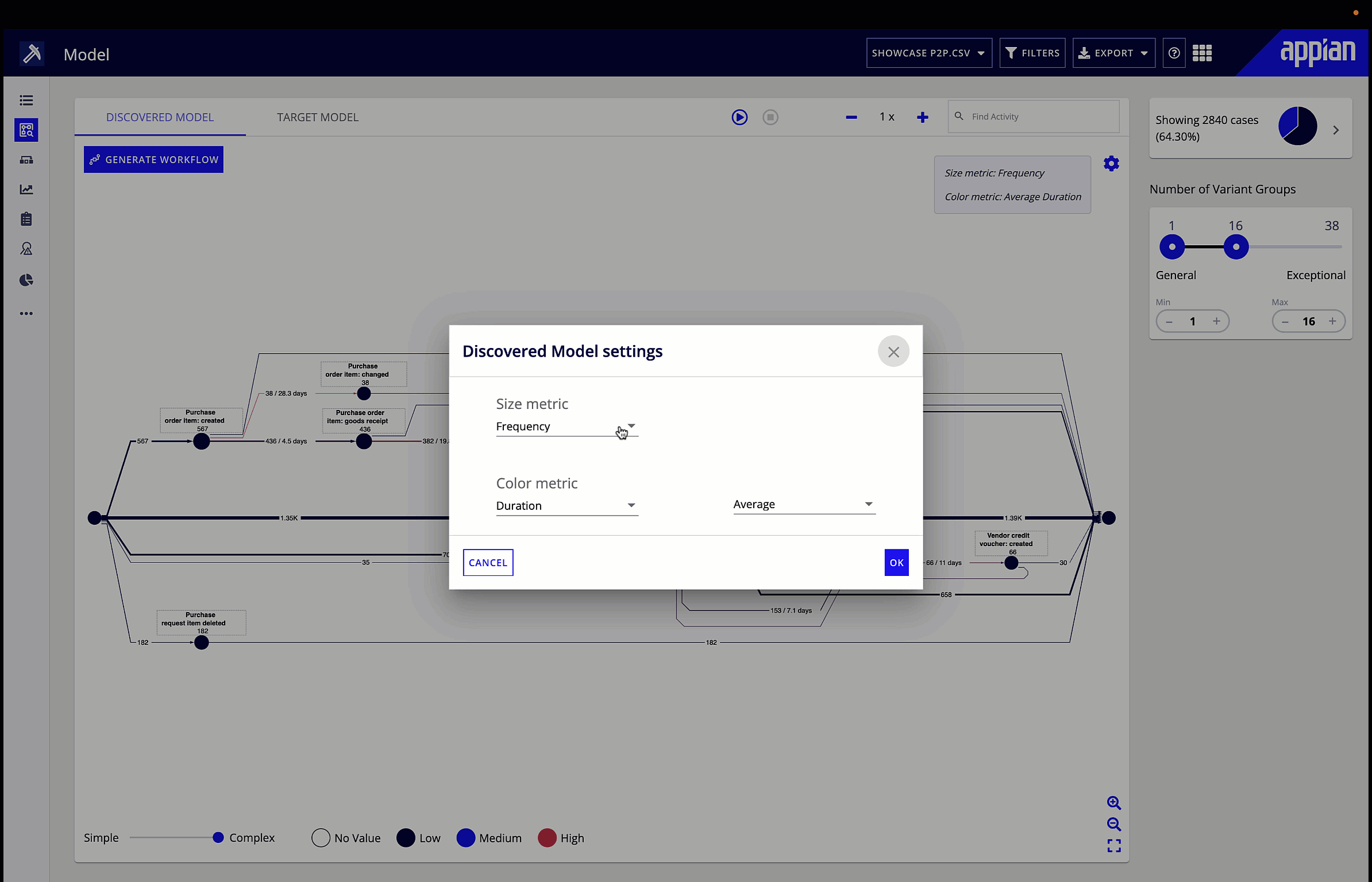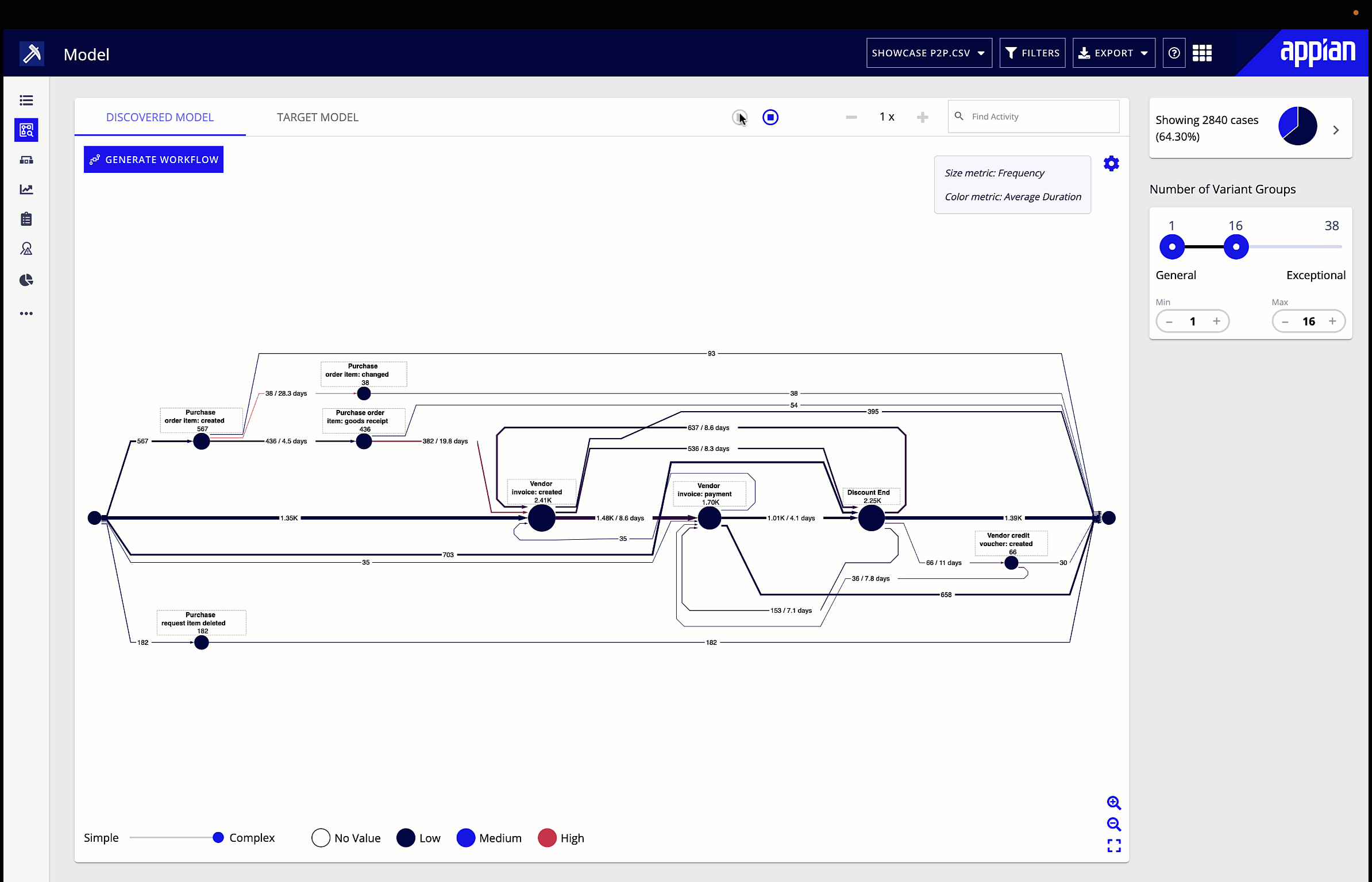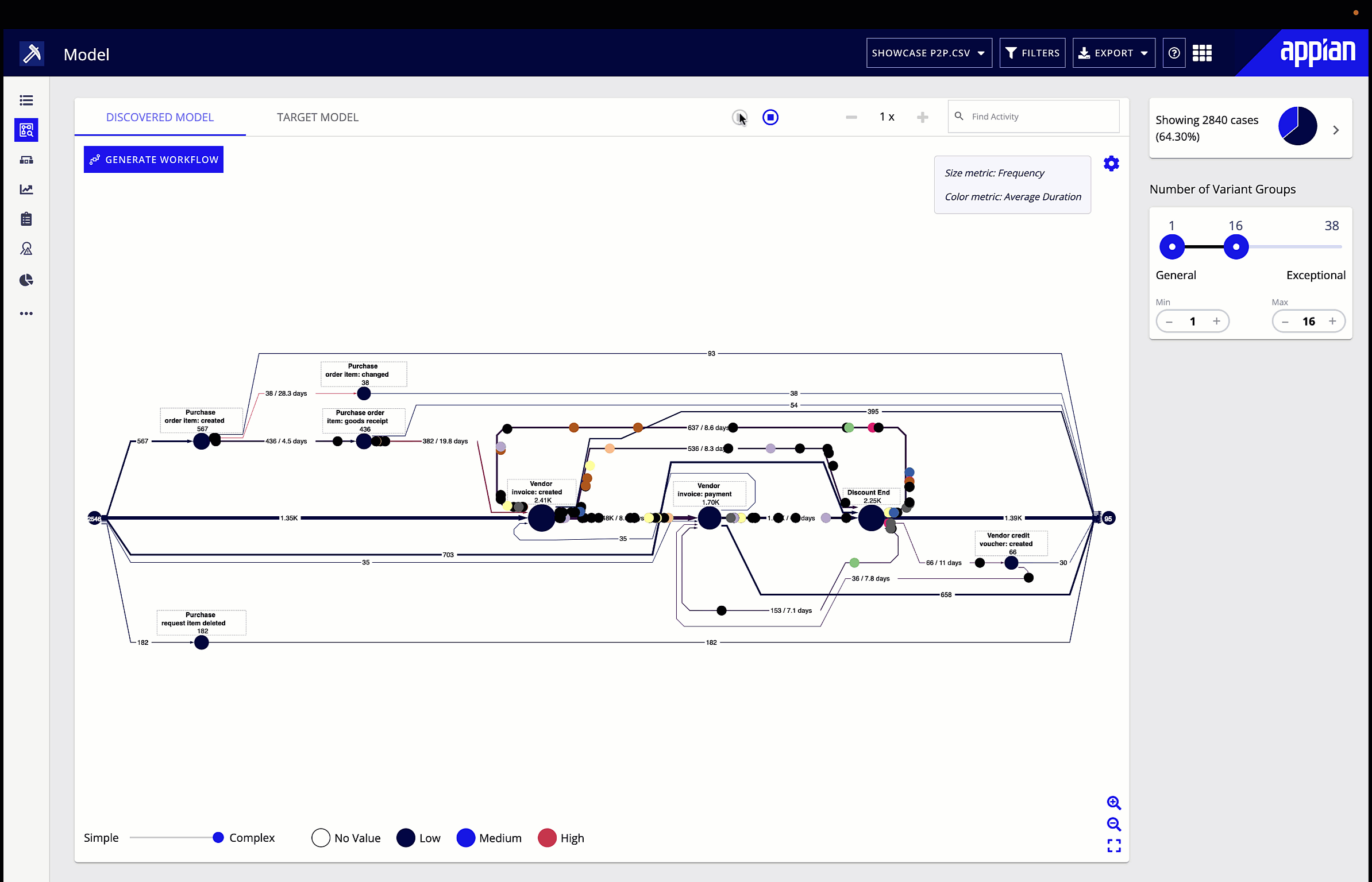
The other drawback to traditional methods of process analysis is that continuous improvement is difficult. When it’s a big lift to review even one process, analysts may not be able to circle back to that process for months if at all. This makes it difficult to see whether changes met business goals. Meanwhile, once set up the first time, process mining can be run regularly to continuously monitor a process. Rather than making changes and never having the time or resources to see the effect of those changes, you can run another analysis and quickly have fresh data to evaluate.
How to conduct a bottleneck analysis.
To conduct a bottleneck analysis with process mining, you’ll need to define, prepare, analyze, improve, and monitor—all components of a strong process improvement plan.
1. Define.
To start, determine the business goals for your analysis. Your business goals—often KPIs or other metrics—will then guide your decision about which process to analyze first, which includes the scope of what steps you’ll be analyzing. This scope and mission will help you clearly define a first increment and find the key stakeholders that will help drive the analysis.
2. Prepare.
Once your goals and measures are defined, you need to access the data that will back your analysis. Ensure the data sets are uniformly formatted. You’ll need to work with IT to determine what data you’ll need and where such data lives. Then, process mining steps in to take out the manual labor. Process mining connects to your data sources, then extracts and transforms your data to the necessary format for analysis. All you need to do next is define your ideal process model—using a BPMN or process mining editor—and you’re ready to start your analysis.
3. Analyze.
Process mining gives you a visualization of your process flow, performance, and deviations. Start by looking for the symptoms of bottlenecks we talked about earlier, and explore performance in the different metrics or KPIs you’ve chosen. You can also filter the visualization by certain attributes, for example, looking only at the process flow and performance in a particular region. Big red dots, bolded red lines, and densely dotted lines will make any patterns obvious to the business user. You can then leverage root cause analysis to suggest underlying causes of identified inefficiencies.
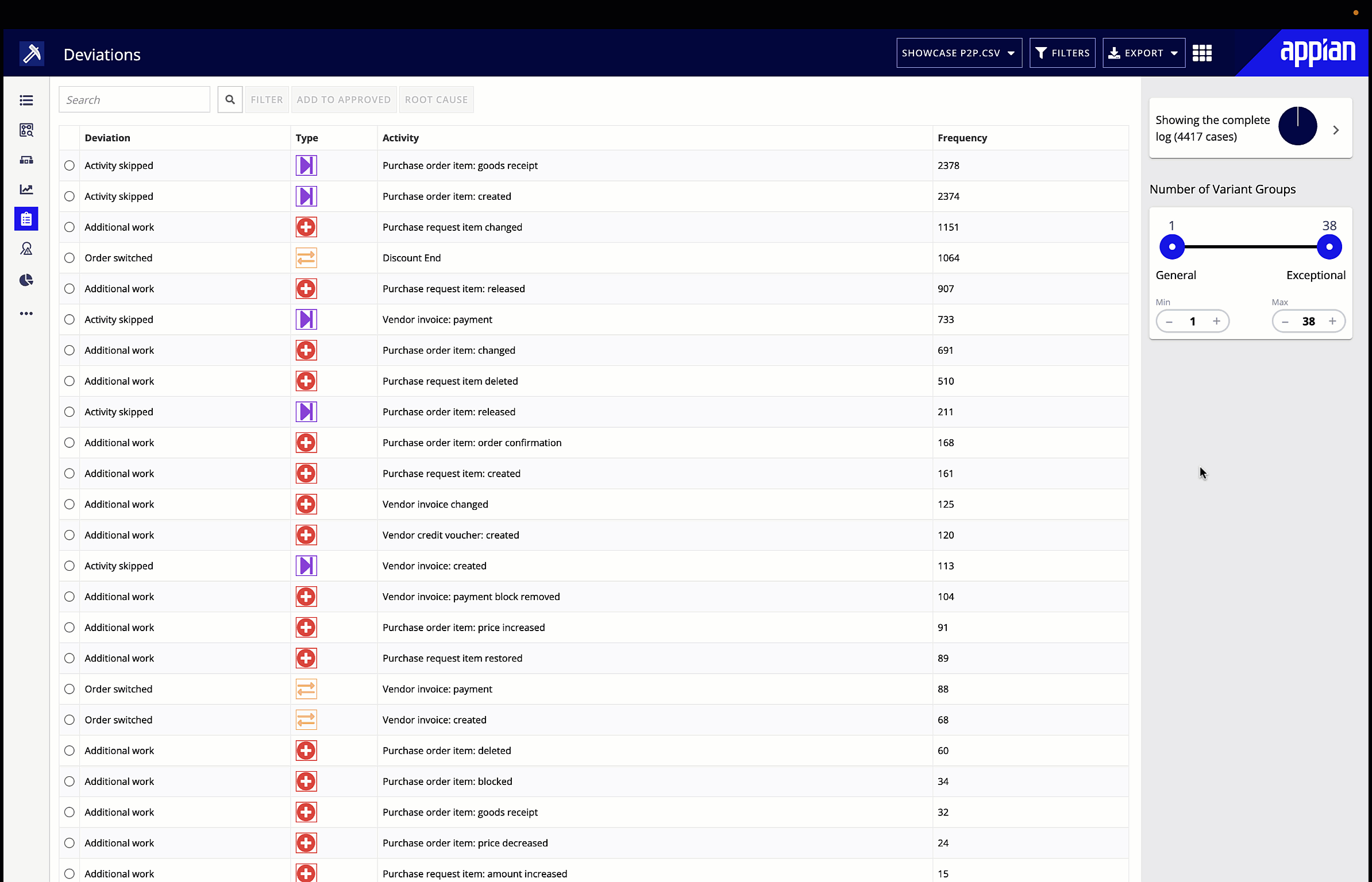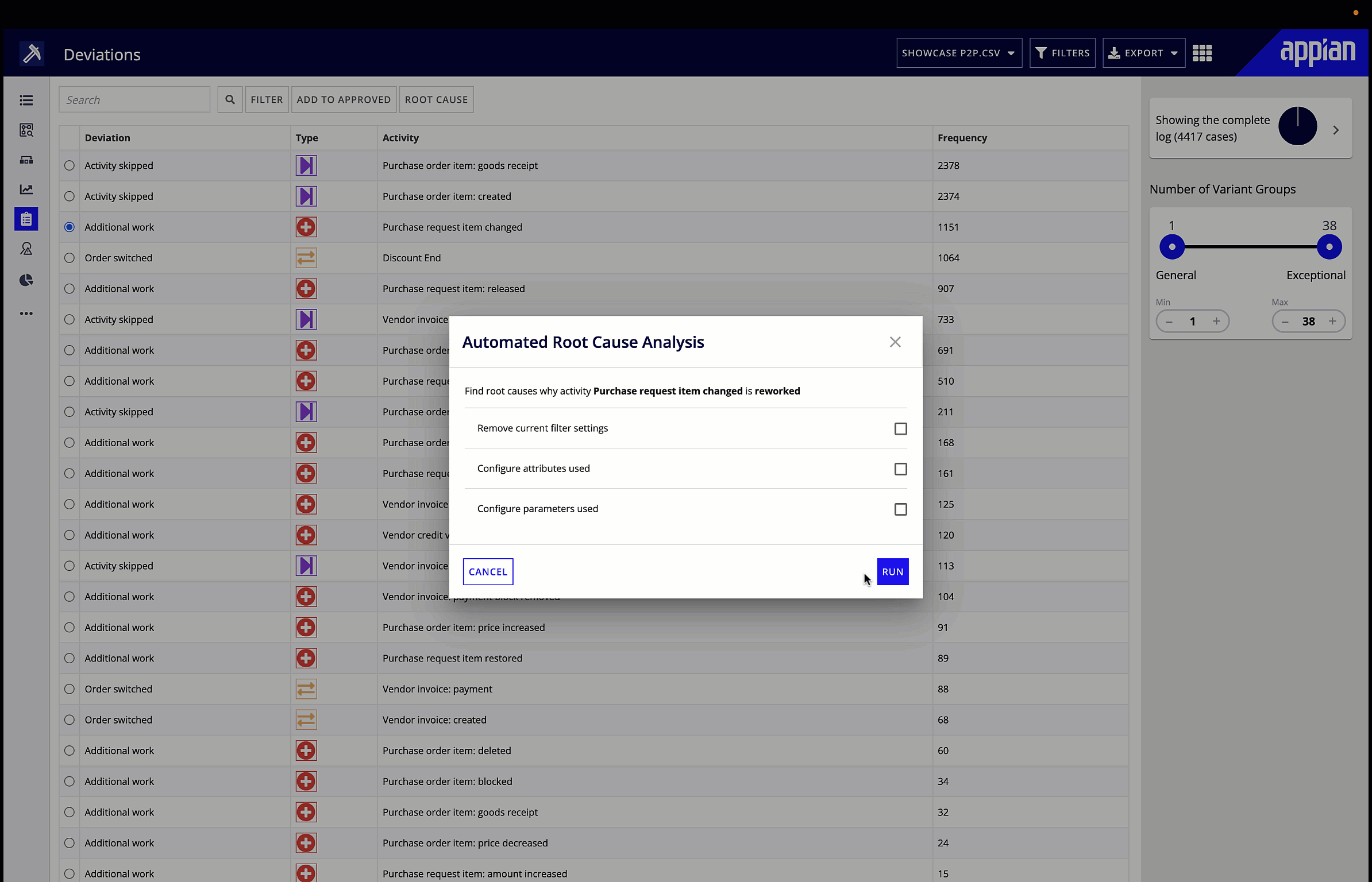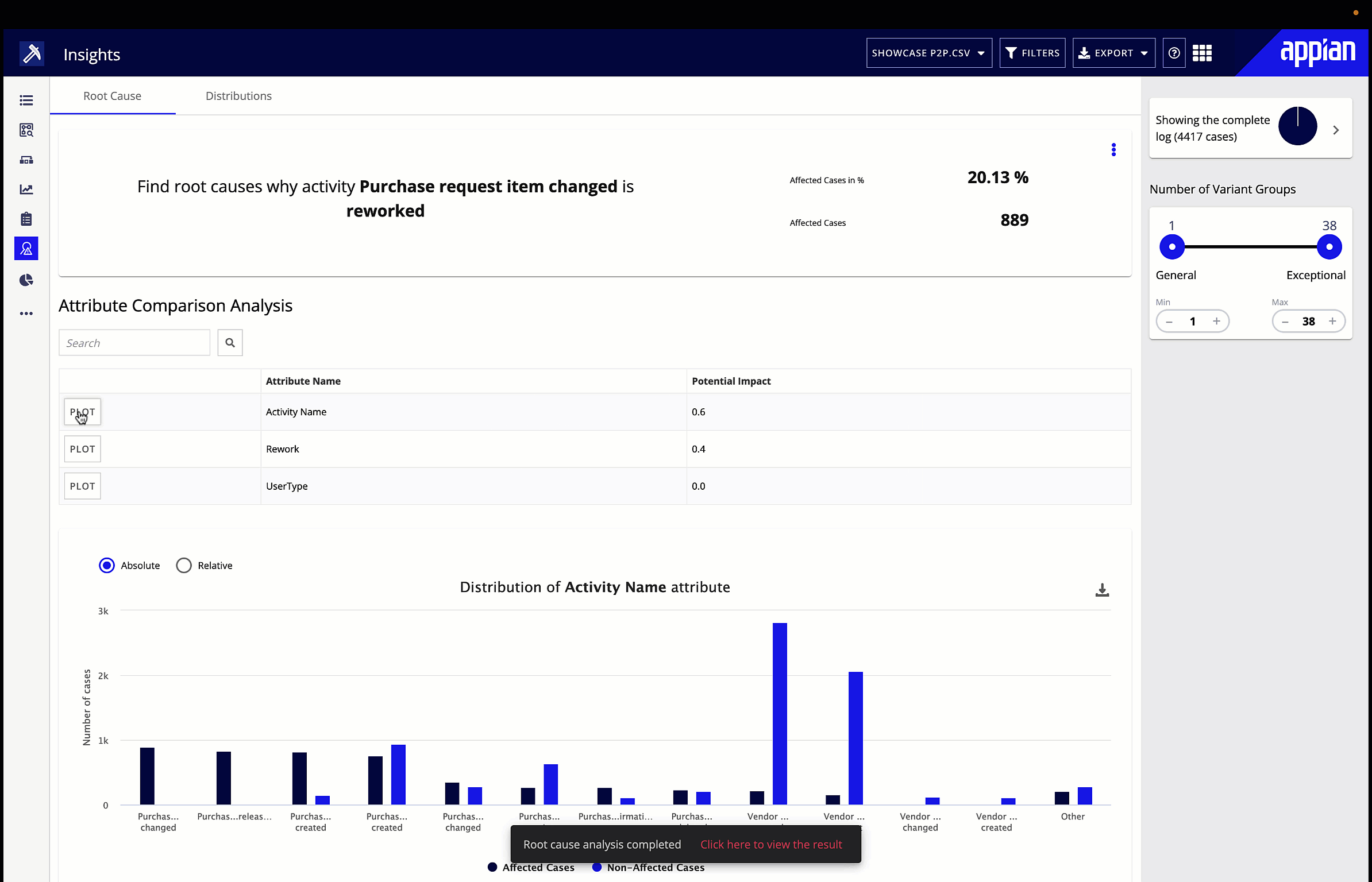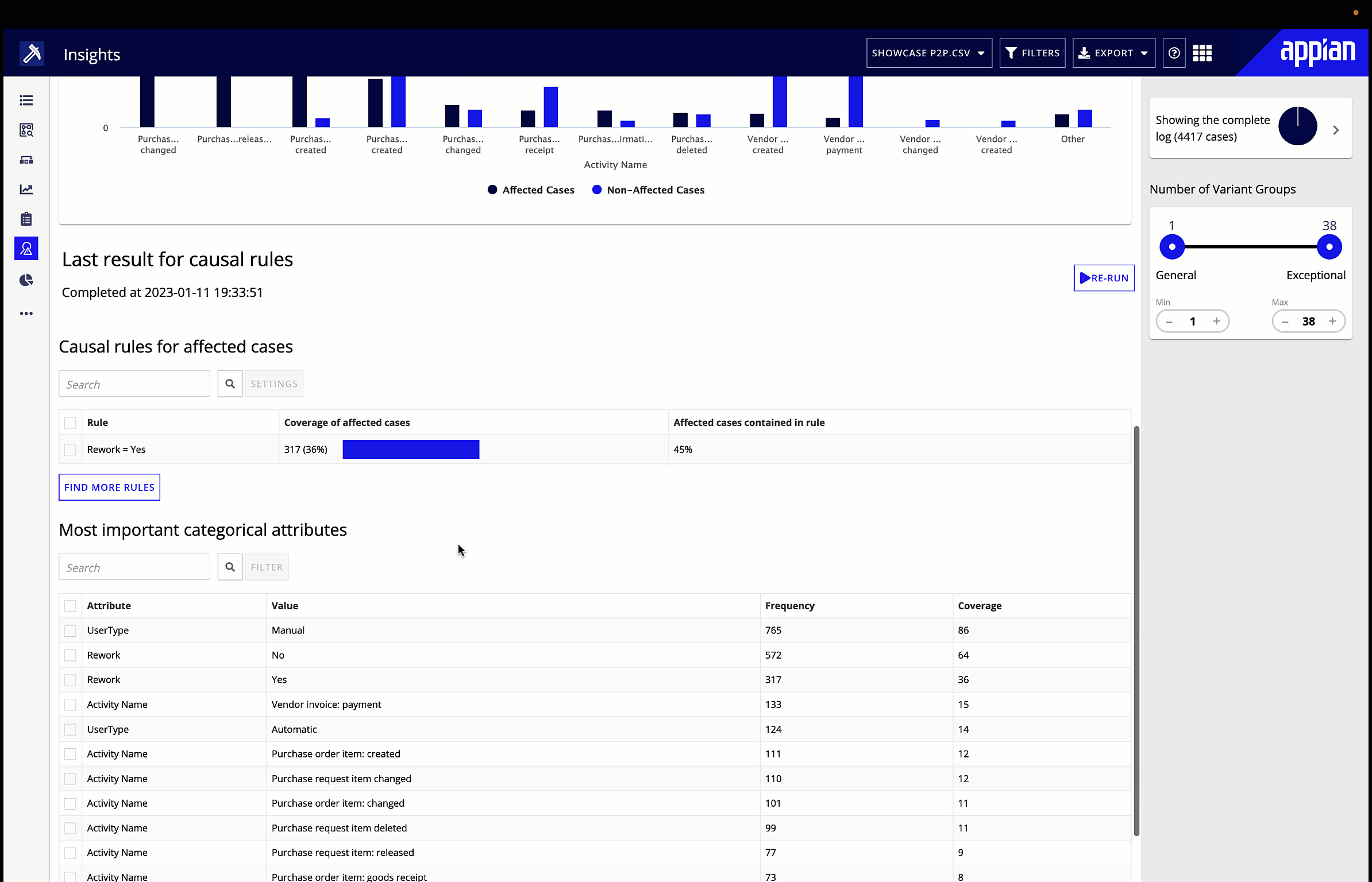
4. Improve.
Now that you have your findings, it’s time to implement those data-driven changes. The solution will depend on the specific bottleneck you’ve found. For example, consider how you might solve the bottleneck examples we’ve identified:
- Lack of access.
In order to maintain data security while also improving data accessibility, utilize a data fabric to grant and monitor data access to authorized individuals. This way, you ensure that needed data is never omitted when sharing with reviewers. - Lack of standardization.
Workflow tools and applications can standardize and enforce the expected process flow. This can significantly decrease auditing complexity while improving process performance and observability. - Lack of specialization.
Reorganizing teams or adding a checkbox that would divert process flows can help alleviate the burden of unnecessary process steps. Workflow tools can also be used to implement these changes, as well as help the auditability of the new process flow. - Lack of automation and/or improper application of automation.
Tools like RPA and IDP can be used to automate rote or error-prone tasks to save employee time and improve accuracy. Be careful, however, to analyze the use case of the automation and pick the correct tool. For example, RPA can be used to implement capabilities of IPaaS solutions, but these require significantly more maintenance as UIs change over time. In a market where automation vendors are consolidating, it is more important than ever to invest in a unified platform capable of addressing the right problems with the right tools.
5. Monitor.
Process mining works to impact, not just to completion—you can measure the impact of your changes and continue to iteratively optimize your process. Process mining makes the continuous cycle of review, mining, analysis, and data-driven decision-making scalable and effective. Building a culture of continuous improvement helps your organization become more efficient over time.
Bottleneck analysis made objective.
When looking to cut waste and inefficiencies, process mining gives you an objective way to identify what provides value and what doesn’t. Plus, with process mining, you can spend less time on the painstaking work of data collection, and put that time back into analyzing and improving more processes, faster.
Want to supercharge process efficiency with process mining? Read about six key considerations from KPMG and Appian.